Last updated: April 28, 2026
Tracing Node.js Services with OpenTelemetry (Complete Guide)
Distributed tracing captures the complete journey of a request as it moves through every service it touches. Each operation is recorded as a span, including its timing, status, and relevant contextual attributes.
OpenTelemetry is the standard framework for producing this data and its Node.js SDK allows you to instrument your application automatically and start collecting traces with minimal setup.
In this guide, you'll instrument a two-service Node.js application from scratch. You'll begin with auto-instrumentation to establish baseline visibility, then refine it using environment variables and SDK configuration. Finally, you'll add manual spans to capture business logic that auto-instrumentation cannot observe.
As you progress, you'll use the collected traces to uncover two real performance problems that are invisible in logs. By the end, you'll know how to produce traces that help you debug production systems.
If you're new to distributed tracing, our guide on how distributed tracing works in microservices introduces the core concepts. For a deeper look at how OpenTelemetry tracing works at the instrumentation level, see our dedicated explainer.
Prerequisites
- Docker and Docker Compose
- Node.js 24+ and npm
- A terminal and a browser
- Basic familiarity with Express and REST APIs
Setting up the demo application
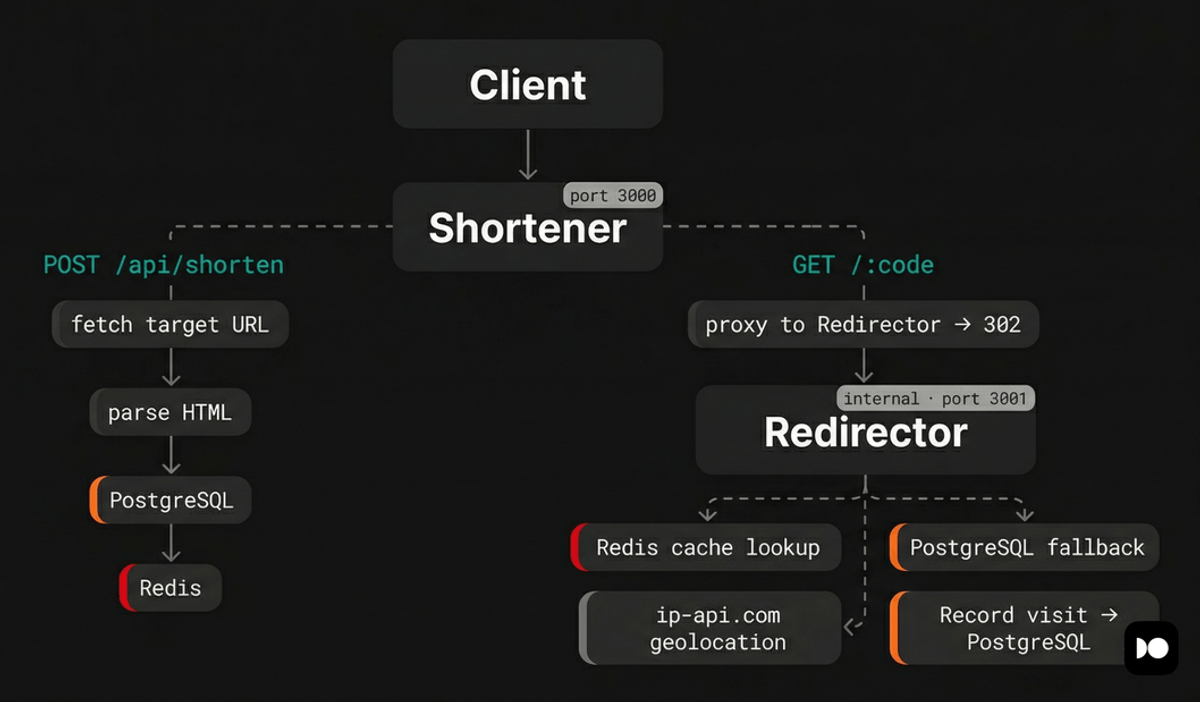
The application you'll instrument is a URL shortener called Snip. It consists of two Node.js services backed by PostgreSQL and Redis:
-
Shortener is the public-facing service that accepts URLs from users, fetches metadata (title and description) from the target page, stores everything in PostgreSQL, caches the mapping in Redis, and serves a web UI. When a user visits a short URL, this service proxies the request to the Redirector.
-
Redirector resolves short codes to original URLs. It checks Redis first, falls back to PostgreSQL on a cache miss, records visit analytics (including IP geolocation via the free ip-api.com service), and returns the original URL to the Shortener, which issues the redirect to the client.
This architecture means a single redirect request flows through both services, hitting Redis, PostgreSQL, and an external API along the way. That's exactly the kind of multi-hop, multi-dependency flow where distributed tracing earns its keep.
Clone the repository, then change into the project directory:
1git clone https://github.com/dash0hq/dash0-examples/ && cd nodejs-tracing-starter
At the project root, rename .env.example to .env:
1mv .env.example .env
The .env file is populated with default values that configure the database
credentials, service ports, and internal service URLs:
12345678POSTGRES_USER=postgresPOSTGRES_PASSWORD=postgresPOSTGRES_DB=shortenerDATABASE_URL=postgres://postgres:postgres@db:5432/shortenerREDIS_URL=redis://redis:6379SHORTENER_PORT=3000REDIRECTOR_PORT=3001REDIRECTOR_URL=http://redirector:3001
Now start the services:
1docker compose up -d --build
Once all containers are healthy, open http://localhost:3000 in your browser to
see the Snip UI:
Paste a URL like https://opentelemetry.io/blog/2026/devex-mastodon/ and click
Shorten. The app fetches the page title and description, generates a short
code, and displays the short URL:
Click the short code in the Recent URLs table (or visit it directly) to trigger a redirect. The Shortener proxies the request to the Redirector, which resolves the short code, records the visit, and sends back the original URL. The Shortener then issues a 302 redirect to the browser.
Everything works but you have no visibility into how these services and their dependencies actually interact to produce that result. If a redirect takes five seconds instead of fifty milliseconds, you can't tell which of the operations in the chain caused the delay.
You'll fix that in the next section with OpenTelemetry's zero-code instrumentation.
Auto-instrumentation gives you visibility without code changes
Before writing any tracing code, it's worth understanding how far OpenTelemetry's auto-instrumentation can take you, because for most Node.js applications, it's surprisingly far.
OpenTelemetry provides auto instrumentation libraries for popular Node.js
packages like Express, pg, redis, undici (Node's built-in fetch), and many
others. When loaded before your application code, these libraries monkey-patch
the modules they target to automatically create spans for their operations.
Every inbound HTTP request, every database query, every cache command, and every
outbound fetch() call gets traced without you writing a single line of
instrumentation code.
Auto-instrumentation also handles context propagation across service boundaries.
When the Shortener calls fetch() to reach the Redirector, the instrumentation
automatically injects a
traceparent header
into the outbound request.
On the Redirector side, the SDK extracts this header and continues the same trace. The result is a single distributed trace spanning both services, with no manual wiring required. You'll see exactly how this works once the traces start flowing.
Installing the necessary packages
To get started, you only need to install two packages, set a few environment variables, and the let SDK handle the rest:
12npm install @opentelemetry/api \@opentelemetry/auto-instrumentations-node
Here's what each package does:
@opentelemetry/apidefines the tracing interfaces (creating spans, setting attributes, propagating context). It's deliberately separate from the SDK so that libraries can instrument themselves without pulling in the full implementation.@opentelemetry/auto-instrumentations-nodebundles the SDK, the trace provider, and instrumentation for popular Node.js libraries. When loaded before your application code via the--importflag, it patches these libraries to automatically create spans for their operations.
Verifying auto-instrumentation with the console exporter
Let's confirm that auto-instrumentation is working by printing spans to
stdout. Add the following variables to your .env file first:
1234OTEL_TRACES_EXPORTER=consoleOTEL_METRICS_EXPORTER=noneOTEL_LOGS_EXPORTER=noneNODE_OPTIONS=--import @opentelemetry/auto-instrumentations-node/register
Then reference them in docker-compose.yml for both services. Since each
service needs its own OTEL_SERVICE_NAME, that one stays inline:
123456789101112131415161718192021# docker-compose.ymlservices:shortener:# ... existing config ...environment:# ... existing vars ...OTEL_SERVICE_NAME: shortenerOTEL_TRACES_EXPORTER: ${OTEL_TRACES_EXPORTER}OTEL_METRICS_EXPORTER: ${OTEL_METRICS_EXPORTER}OTEL_LOGS_EXPORTER: ${OTEL_LOGS_EXPORTER}NODE_OPTIONS: ${NODE_OPTIONS}redirector:# ... existing config ...environment:# ... existing vars ...OTEL_SERVICE_NAME: redirectorOTEL_TRACES_EXPORTER: ${OTEL_TRACES_EXPORTER}OTEL_METRICS_EXPORTER: ${OTEL_METRICS_EXPORTER}OTEL_LOGS_EXPORTER: ${OTEL_LOGS_EXPORTER}NODE_OPTIONS: ${NODE_OPTIONS}
NODE_OPTIONS tells Node.js to load the auto-instrumentation registration
module before your application code runs. This gives the SDK a chance to patch
Express, pg, redis, undici, and other supported packages before your
application imports them.
Setting OTEL_TRACES_EXPORTER to console directs the SDK to print every
completed span to stdout, while setting the metrics and logs exporters to
none keeps the output focused on traces.
Once you're done, rebuild and restart the containers:
1docker compose up -d --build
Then shorten a URL and follow the redirect to generate some spans. When you check the service logs:
1docker compose logs shortener redirector
You should see span objects printed to the terminal, each containing a name,
traceId, duration, resource, and attributes field. If these objects are
showing up, the SDK is working and auto-instrumentation is active:
1234567891011121314151617181920212223242526272829303132333435{resource: {attributes: {'service.name': 'shortener','process.pid': 19,'process.executable.name': 'node','process.executable.path': '/usr/local/bin/node','process.command_args': [ '/usr/local/bin/node', '/app/shortener/index.js' ],[...]}},instrumentationScope: {name: '@opentelemetry/instrumentation-http',version: '0.214.0',schemaUrl: undefined},traceId: '64e74aaba02ba88664bef3402dfa75d2',parentSpanContext: undefined,traceState: undefined,name: 'GET',id: 'b6a49f7987aed7f8',kind: 1,timestamp: 1774511881199000,duration: 37289.78,attributes: {'http.url': 'http://localhost:3000/api/urls','http.host': 'localhost:3000','net.host.name': 'localhost','http.method': 'GET',[...]},status: { code: 0 },events: [],links: []}
You might notice the span attributes use deprecated naming conventions like
http.methodandhttp.url. The OpenTelemetry semantic conventions have since moved tohttp.request.methodandurl.full, and newer versions of the instrumentation libraries are migrating to the updated names. The distinction doesn't affect how tracing works, but it's worth knowing when you're querying or filtering spans in your backend.
Under the resource > attributes object, you should observe that service.name
is set to the configured OTEL_SERVICE_NAME. This attribute is carried on every
signal the service emits, and
it's the primary key
that observability backends use for filtering and grouping.
Without it, your telemetry lands under a generic name like
unknown_service:node, which makes it indistinguishable from any other service
that also forgot to set one. When something breaks at 2 AM, that's the last
situation you want to be in, so if you see the wrong name, double-check that the
variable is set correctly in docker-compose.yml before moving on.
The other attributes in the resource object (host.arch, process.pid,
process.runtime.version, and so on) were populated automatically by the SDK's
resource detectors. By default, the Node.js SDK uses all available detectors,
but you can control that through the OTEL_NODE_RESOURCE_DETECTORS environment
variable:
1OTEL_NODE_RESOURCE_DETECTORS="host,env,process,container"
For attributes that can't be detected automatically, you can set them explicitly
through OTEL_RESOURCE_ATTRIBUTES in your .env:
1OTEL_RESOURCE_ATTRIBUTES=deployment.environment.name=development,service.version=1.0.0
In production, the Collector is the best place for resource enrichment because it works consistently across all services regardless of language or runtime. The resource detection processor can automatically attach cloud provider and container metadata, while the Kubernetes attributes processor adds pod, namespace, deployment, and node information to every signal passing through the pipeline.
Setting up the OpenTelemetry Collector and Jaeger
You've now confirmed that spans are being created with the right service identity. But to actually explore traces visually, you need to send them to a tracing backend.
In this section, you'll set up an
OpenTelemetry Collector
and Jaeger, then
switch the exporter from console to
otlp so the SDK
starts forwarding spans through the Collector.
Create a Collector configuration file at your project root:
1234567891011121314151617181920# otelcol.yamlreceivers:otlp:protocols:http:endpoint: 0.0.0.0:4318exporters:otlp/jaeger:endpoint: jaeger:4317tls:insecure: truedebug:verbosity: basicservice:pipelines:traces:receivers: [otlp]exporters: [otlp/jaeger, debug]
The Collector listens for OTLP over HTTP on port 4318 (matching what the SDK
will send) and exports them to Jaeger over gRPC. The
debug exporter also
prints a summary to the Collector's stdout, which is useful for verifying that
spans are actually flowing through the Collector pipeline.
Now add the Collector and Jaeger services to your docker-compose.yml:
12345678910111213141516171819# docker-compose.ymlservices:# [...existing services]collector:image: otel/opentelemetry-collector-contrib:0.148.0volumes:- ./otelcol.yaml:/etc/otelcol-contrib/config.yamlports:- 4318:4318networks:- appjaeger:image: jaegertracing/jaeger:2.16.0ports:- 16686:16686- 4317:4317networks:- app
With this infrastructure in place, update your .env to switch from the console
exporter to OTLP and specify the correct endpoint through
OTEL_EXPORTER_OTLP_ENDPOINT:
12OTEL_TRACES_EXPORTER=otlpOTEL_EXPORTER_OTLP_ENDPOINT=http://collector:4318
Then reference the new endpoint variable in docker-compose.yml for both
services, and add a dependency on the Collector so the services don't start
before it's ready:
1234567891011121314151617181920services:shortener:# ... existing config ...environment:# ... existing vars ...OTEL_EXPORTER_OTLP_ENDPOINT: ${OTEL_EXPORTER_OTLP_ENDPOINT}depends_on:# ... existing deps ...collector:condition: service_startedredirector:# ... existing config ...environment:# ... existing vars ...OTEL_EXPORTER_OTLP_ENDPOINT: ${OTEL_EXPORTER_OTLP_ENDPOINT}depends_on:# ... existing deps ...collector:condition: service_started
Rebuild and bring up all the services now with:
1docker compose up -d --build
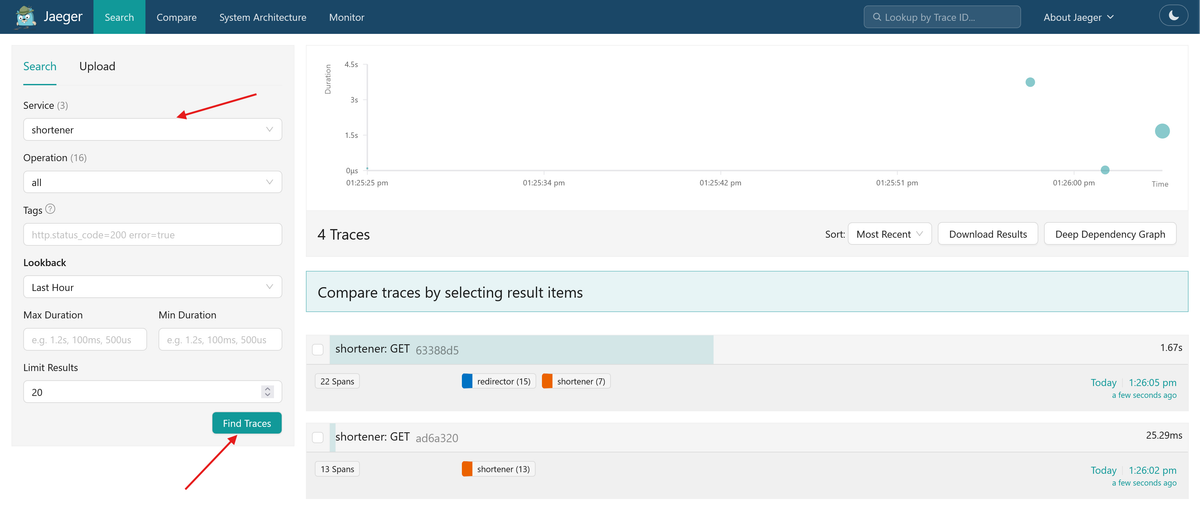
Once everything is running, shorten some URLs through the UI to generate some
traces and navigate to the shortened URLs. Then open the Jaeger UI at
http://localhost:16686, select the shortener service, and click Find
Traces.
Click on the trace for the redirect request to see something like this:
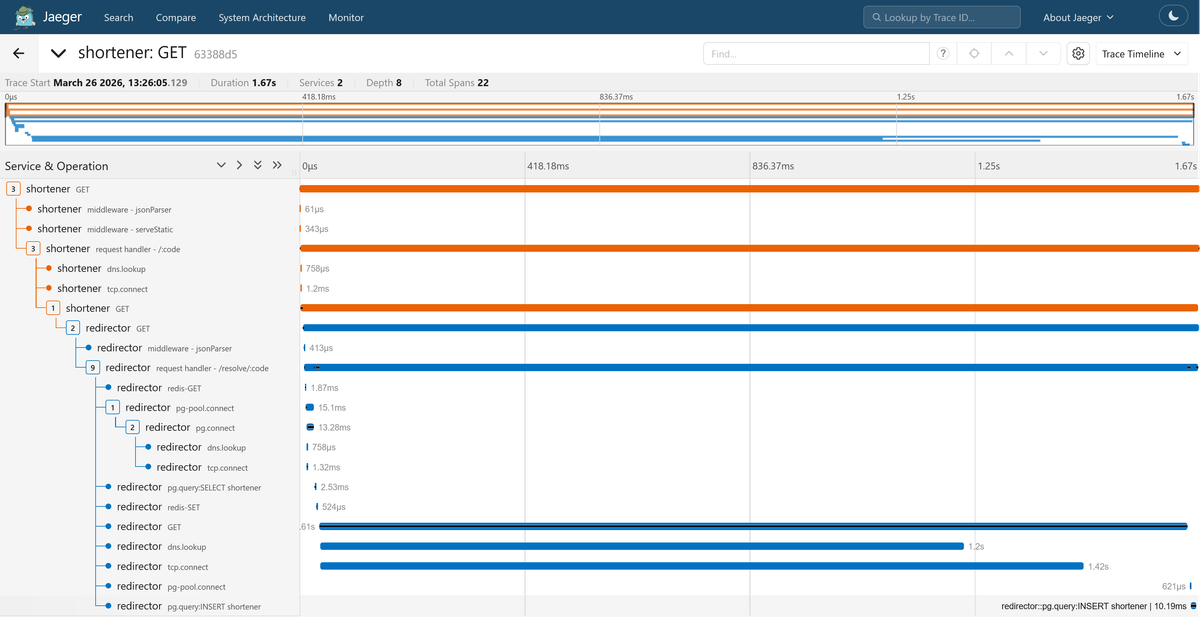
This is a distributed trace spanning 22 spans across both services. The root
span is the Shortener's GET request, with Express middleware spans
(jsonParser, serveStatic) and the request handler - /:code route nested
beneath it. You can also see dns.lookup and tcp.connect spans that the
auto-instrumentation captured at the network level.
The outbound HTTP call to the Redirector appears as a child GET span on the
Shortener, and beneath it the Redirector's own GET and request handler -
/resolve/:code spans begin.
Inside the Redirector's handler, you can see the full resolution sequence: a
redis-GET for the cache lookup, a pg.query:SELECT for the database fallback
(along with pg-pool.connect and pg.connect spans for the connection setup),
a redis-SET to re-populate the cache, then the outbound GET to ip-api.com
for geolocation (with its own dns.lookup and tcp.connect children), and
finally a pg.query:INSERT to record the visit.
All of this happened without writing a single line of tracing code. The auto-instrumentation libraries handled span creation, context propagation, and attribute population for every HTTP request, database query, and Redis command.
Customizing the auto-instrumentation
The default auto-instrumentation gives you broad coverage, but looking at the trace you just generated, two things stand out that are worth tuning.
Filtering out noisy spans
The trace includes spans for low-level operations like dns.lookup,
tcp.connect, and pg-pool.connect. These are created because the
auto-instrumentation bundle patches every library it recognizes by default,
including networking primitives that sit beneath the higher-level libraries you
actually care about. For most debugging workflows, these spans add clutter
without diagnostic value.
The OTEL_NODE_ENABLED_INSTRUMENTATIONS environment variable lets you whitelist
only the instrumentations you want. Add it to your .env:
1OTEL_NODE_ENABLED_INSTRUMENTATIONS=http,express,pg,redis,undici,router
Then reference it in docker-compose.yml for both services:
1OTEL_NODE_ENABLED_INSTRUMENTATIONS: ${OTEL_NODE_ENABLED_INSTRUMENTATIONS}
You can find the full list of instrumentation names in the
auto-instrumentations-node README.
The names you pass to this variable match the suffix of each package name, so
@opentelemetry/instrumentation-pg becomes pg,
@opentelemetry/instrumentation-express becomes express, and so on.
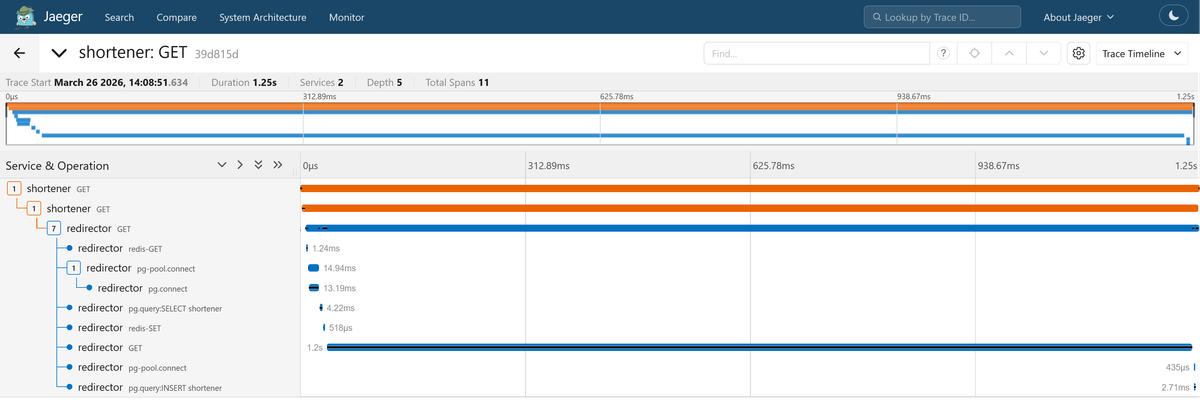
After restarting, the traces in Jaeger will be significantly cleaner, showing
only HTTP, Express, PostgreSQL, Redis, and outbound fetch operations without
the low-level networking noise.
If you prefer to use a blocklist instead, use
OTEL_NODE_DISABLED_INSTRUMENTATIONS instead.
Customizing span names
Some customizations go beyond what environment variables can express. For
example, the spans produced by the http and undici instrumentations show
only "GET" or "POST" without any indication of which endpoint was called or
which dependency was targeted. When the Shortener calls the Redirector, or the
Redirector calls ip-api.com, those spans all look identical in Jaeger.
To fix this, you need programmatic access to the SDK configuration. First, install the OTLP exporter and the SDK packages:
12npm install @opentelemetry/sdk-node \@opentelemetry/exporter-trace-otlp-proto
Then create a lib/otel.js file that initializes the SDK explicitly:
123456789101112131415161718192021222324252627// lib/otel.jsimport { getNodeAutoInstrumentations } from "@opentelemetry/auto-instrumentations-node";import { OTLPTraceExporter } from "@opentelemetry/exporter-trace-otlp-proto";import { NodeSDK } from "@opentelemetry/sdk-node";const sdk = new NodeSDK({traceExporter: new OTLPTraceExporter(),instrumentations: [getNodeAutoInstrumentations({"@opentelemetry/instrumentation-undici": {requestHook(span, request) {const url = new URL(request.origin + request.path);span.updateName(`${request.method} ${url.host}${url.pathname}`);},},"@opentelemetry/instrumentation-http": {requestHook(span, request) {span.updateName(`${request.method} ${request.path}`);},},}),],});sdk.start();process.on("SIGTERM", () => sdk.shutdown());
Each instrumentation package in the getNodeAutoInstrumentations config is
referenced by its full npm package name (for example,
@opentelemetry/instrumentation-http), and the object you pass as its value
maps directly to the options that package accepts.
To find what's available for a given instrumentation, check the auto-instrumentations-node GitHub README, which lists every supported package along with a link to its README which documents the full set of configuration options.
In this example, you'll customize only the http and undici instrumentations.
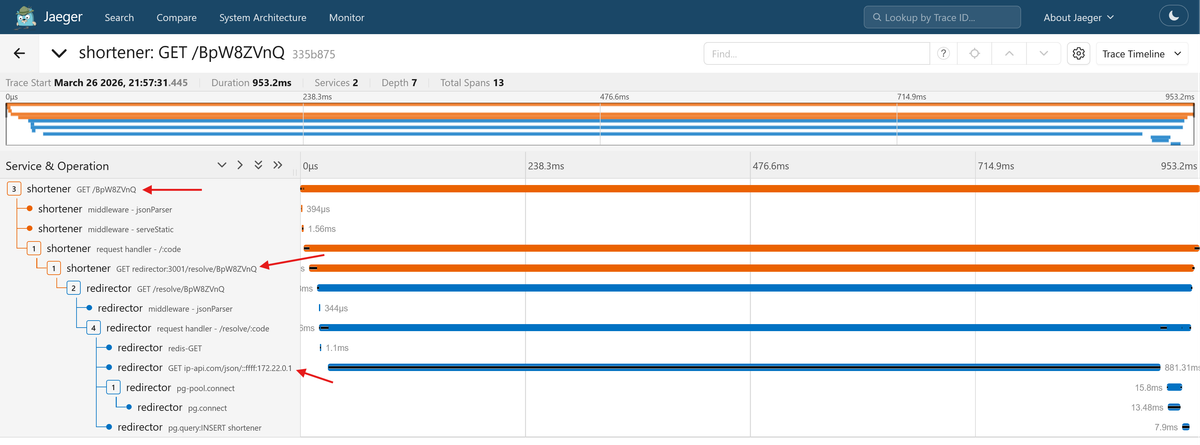
The http hook renames inbound server spans from a bare GET to something like
GET /resolve/BpW8ZVnQ, while the undici hook renames outbound fetch()
spans to include the target host (like GET redirector:3001/resolve/BpW8ZVnQ).
Depending on the specific instrumentation library, you can also attach custom attributes to spans based on request or response data, ignore specific routes or endpoints to keep noise out of your traces, capture request and response headers as span attributes, amongst other things!
The SIGTERM handler ensures the SDK flushes any buffered spans before the
process exits. Without it, spans that are still in the export buffer when the
process terminates are silently lost.
To see this in action, update your package.json scripts as follows:
123456{"scripts": {"shortener": "node --import ./lib/otel.js shortener/index.js","redirector": "node --import ./lib/otel.js redirector/index.js"}}
Then remove the NODE_OPTIONS line from .env, since its been superseded by
the --import flag. The remaining OTEL_* environment variables stay unchanged
since the programmatic setup reads them the same way the zero-code setup did.
After restarting the services, both inbound and outbound HTTP spans in Jaeger will carry descriptive names:
Tracing your business logic
Auto-instrumentation combined with the customizations from the previous section already gives you a substantial amount of visibility.
Without writing any tracing code in your application, you can see the full lifecycle of a request as it flows from the Shortener to the Redirector, identify which database queries and Redis commands are executed along the way, measure how long each operation takes relative to the overall request duration, and trace outbound calls to external dependencies like ip-api.com.
For many debugging scenarios, this level of detail is enough to pinpoint slow queries, failing dependencies, or unexpected call patterns.
Where auto-instrumentation falls short is inside your business logic. The metadata extraction in the Shortener, the HTML parsing, the visit recording: these are all invisible in the current traces because no library boundary exists for the auto-instrumentation to hook into.
Manual instrumentation fills that gap by letting you wrap specific operations in spans, attach attributes that capture what happened and why, and record errors with enough context to debug them from the trace alone.
Instrumenting the metadata extraction function
The extractMetadata() function in shortener/metadata.js fetches a target
URL, checks the response, and parses the HTML to extract a title and
description.
Several things can go wrong along the way: the fetch might time out, the
response might not be HTML or it might lack a title tag entirely. None of these
failures would surface in the auto-instrumented trace because they happen inside
application logic, not at a library boundary.
By instrumenting this function with additional spans, you'll be able to see how long metadata extraction takes as a distinct operation within the trace, capture why it returned null through span attributes, and record exceptions with full stack traces so failed extractions are visible in your observability tool.
Here's the instrumented version of shortener/metadata.js:
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657// shortener/metadata.jsimport { SpanStatusCode, trace } from "@opentelemetry/api";import * as cheerio from "cheerio";import { logger } from "../lib/logger.js";const tracer = trace.getTracer("shortener.metadata");export async function extractMetadata(url) {return tracer.startActiveSpan("extract-metadata", async (span) => {span.setAttribute("url.full", url);try {const response = await fetch(url, {headers: {"User-Agent": "Shortener/1.0",},signal: AbortSignal.timeout(5000),});const contentType = response.headers.get("content-type") || "";if (!response.ok || !contentType.includes("text/html")) {throw new Error(`Unusable response: ${response.status} ${contentType}`);}const html = await response.text();span.setAttribute("metadata.html_bytes", html.length);const $ = cheerio.load(html);const title =$('meta[property="og:title"]').attr("content") ||$("title").first().text().trim() ||null;const description =$('meta[property="og:description"]').attr("content") ||$('meta[name="description"]').attr("content") ||null;span.setAttribute("metadata.has_title", title !== null);span.setAttribute("metadata.has_description", description !== null);return { title, description };} catch (err) {span.setStatus({code: SpanStatusCode.ERROR,message: err.message,});logger.error({ err }, "Failed to extract metadata");return { title: null, description: null };} finally {span.end();}});}
The trace.getTracer() call is how you obtain a tracer for creating manual
spans and you must pass a string (shortener.metadata) to specify the
instrumentation scope name.
While OTEL_SERVICE_NAME identifies which service produced the telemetry
(like shortener or redirector), the scope name identifies which component
within that service produced it.
In your backend, you'll see spans scoped to shortener.metadata (your code)
alongside spans scoped to @opentelemetry/instrumentation-pg or
@opentelemetry/instrumentation-undici (the auto-instrumentation libraries),
all within the same shortener service.
This tracer comes from the same TracerProvider that the SDK initialized in
otel.js, so manual spans you create with it are automatically part of the same
traces that auto-instrumentation initiates.
If you create a span inside an Express request handler, it becomes a child of the auto-instrumented HTTP span for that request because both share the same active context. This is what makes the two approaches composable: auto-instrumentation provides the scaffolding, and manual spans fill in the details.
When you call tracer.startActiveSpan(), the new span becomes the active span
on the current context. Any spans created inside the callback, including the
auto-instrumented span from the fetch call, automatically become children of
this span. This is how the trace tree grows without you manually wiring
parent-child relationships.
The catch block logs the error and calls span.setStatus() (which marks the
span as failed in the trace UI). When such log is
correlated with traces with a log bridge,
it becomes automatically available in the span's timeline without having to dig
through a separate log stream.
If you skip either one, failed operations either appear as successful spans or
you'll lack the detail needed to diagnose the failure. The finally block
guarantees that span.end() is called exactly once regardless of which code
path executes, ensuring the span is always exported.
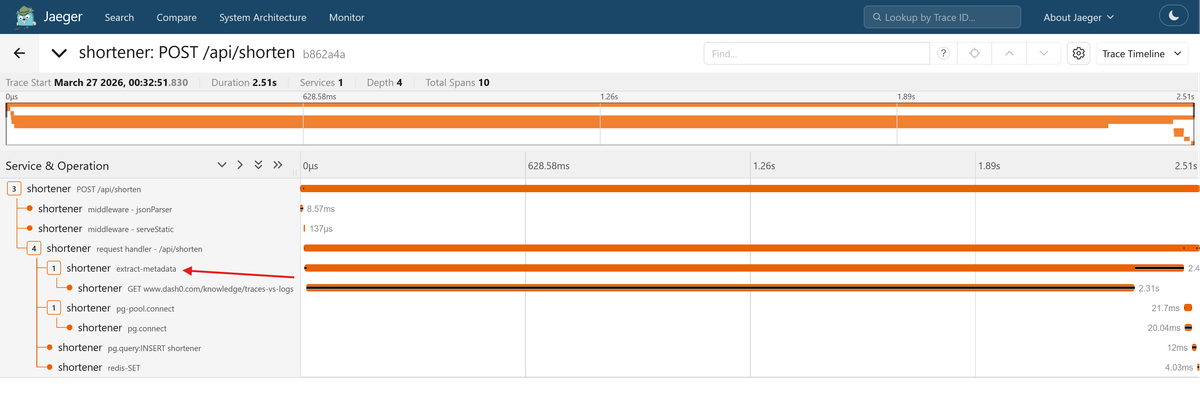
After rebuilding the services and shortening a URL, open the trace for the
POST /api/shorten request in Jaeger. You should see the extract-metadata
span nested under the HTTP server span, with the auto-instrumented outbound
fetch span as its child:
Expand the extract-metadata Tags to see the metadata.has_title,
metadata.has_description, and metadata.html_bytes attributes:
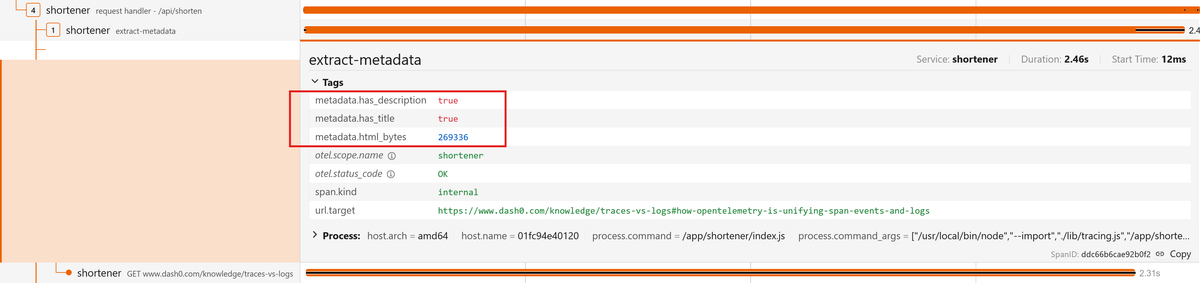
Enriching existing auto-instrumented spans
The manual span you added to extractMetadata() captures an operation that was
previously invisible. But the auto-instrumented spans already in your traces can
also carry business context beyond what the instrumentation libraries record by
default.
The HTTP server span for each request already tracks timing and status; attaching your own attributes to it makes that span searchable and filterable by dimensions that matter to your application.
For example, in the redirect proxy (GET /:code), you can record which short
code was requested and where it resolved to:
123456789101112131415161718192021222324252627282930313233343536// shortener/routes.jsimport { trace } from "@opentelemetry/api";// [...]router.get("/:code", async (req, res) => {const { code } = req.params;try {const response = await fetch(`${REDIRECTOR_URL}/resolve/${code}`, {headers: {"x-forwarded-for": req.ip || req.socket.remoteAddress,"user-agent": req.get("user-agent") || "unknown",},signal: AbortSignal.timeout(5000),redirect: "manual",});const body = await response.json();if (!response.ok) {return res.status(response.status).json(body);}const span = trace.getActiveSpan();if (span) {span.setAttribute("shortener.short_code", code);span.setAttribute("shortener.original_url", body.original_url);}res.redirect(302, body.original_url);} catch (err) {console.error("Redirect proxy failed:", err);res.status(502).json({ error: "Redirector service unavailable" });}});
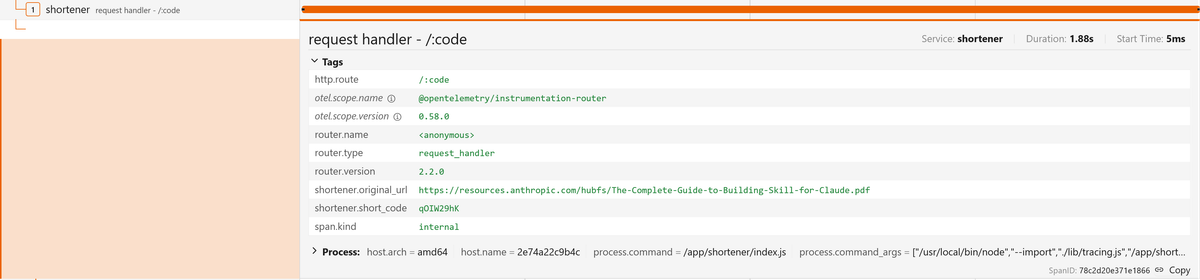
And in the Redirector's resolve/:code handler:
123456789101112131415161718192021222324// redirector/routes.jsimport { trace } from "@opentelemetry/api";// [...]router.get("/resolve/:code", async (req, res) => {const { code } = req.params;try {// Step 1: Check Redis cacheconst cached = await redis.get(`urls:${code}`);const span = trace.getActiveSpan();if (span) {span.setAttribute("shortener.short_code", code);span.setAttribute("shortener.cache_hit", !!cached);}// [...]} catch (err) {console.error("Resolve failed:", err);res.status(500).json({ error: "Internal server error" });}});
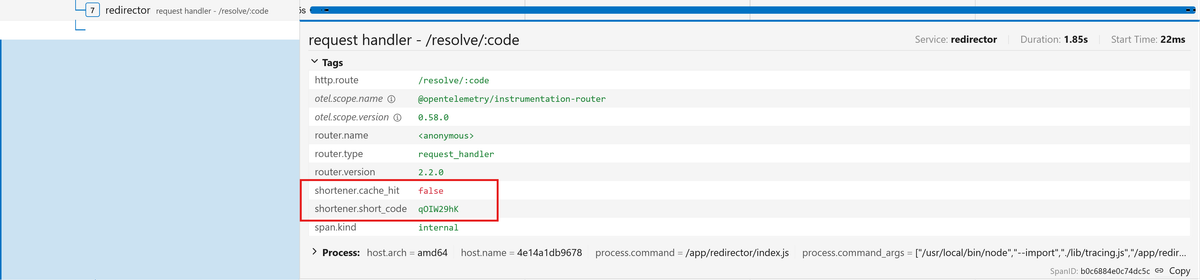
The shortener.cache_hit attribute is particularly valuable because it tells
you immediately whether a redirect served from Redis or fell back to PostgreSQL,
which is the most common performance-relevant distinction in this application.
You'll see this attribute pay off in the debugging section later.
The if (span) guard is a defensive pattern worth adopting since
getActiveSpan() returns undefined if there's no active span in the current
context (which can happen if the SDK isn't initialized), so the guard prevents
your application code from crashing when tracing is absent.
Also notice that you don't call span.end() here. The auto-instrumentation owns
this span and will end it when the request completes. Calling span.end()
yourself would close the span prematurely, before the handler finishes.
Using traces to debug your services
The instrumentation you've built so far gives you visibility into the structure and timing of every request. Now it's time to put that visibility to work.
The demo application has two subtle performance problems baked in that are invisible from the outside: the app works correctly with no errors and no crashes, but it's doing more work than it needs to. Tracing is how you'll find out.
Finding the N+1 query
Open http://localhost:3000 in your browser to load the Snip UI. It should load
normally and show all your shortened URLs.
Now open Jaeger, find the trace for the GET /api/urls request, and look at the
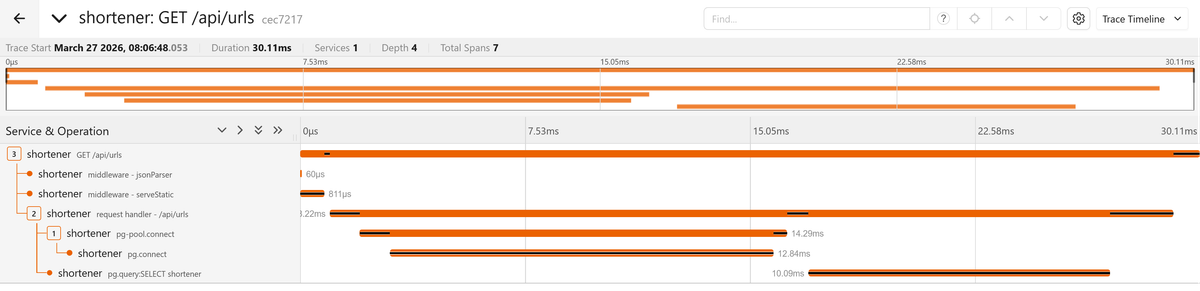
span timeline:
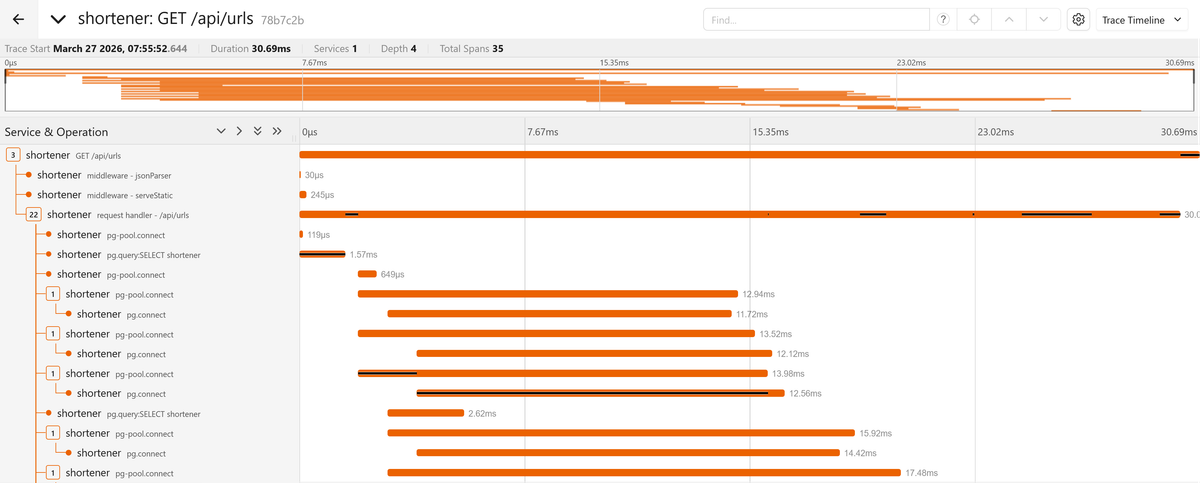
You should see something striking: several spans for what should be a simple
list query. The trace starts with the Express middleware and route handler
spans, then explodes into a cascade of pg-pool.connect, pg.connect, and
pg.query:SELECT shortener spans repeating in sequence.
Each URL in the list triggers its own connection acquisition and count query, and you can see them stacking up across the timeline, each one waiting for the previous to finish. This is a classic N+1 query problem where the code fetches the list of URLs, then loops over each one to query its visit count individually:
12345678910111213141516171819// shortener/routes.jsrouter.get("/api/urls", async (_req, res) => {const result = await db.query("SELECT short_code, original_url, title, description, created_at FROM urls ORDER BY created_at DESC LIMIT 20",);// Fetch visit count for each URL individuallyconst rows = await Promise.all(result.rows.map(async (row) => {const visits = await db.query("SELECT COUNT(*) FROM visits WHERE short_code = $1",[row.short_code],);return { ...row, visit_count: parseInt(visits.rows[0].count, 10) };}),);res.json(rows);});
In your PostgreSQL logs, you'll see successful database queries and nothing looks wrong. Each query completes quickly on its own, but the trace tells a different story: the waterfall of sequential queries adds up, and the total latency is the sum of all of them rather than the cost of any single one.
The fix is a single query with a LEFT JOIN:
12345678910111213141516router.get("/api/urls", async (_req, res) => {const result = await db.query(`SELECT u.short_code, u.original_url,u.title, u.description,u.created_at,COUNT(v.id)::int AS visit_countFROM urls uLEFT JOIN visits vON u.short_code = v.short_codeGROUP BY u.idORDER BY u.created_at DESCLIMIT 20`,);res.json(result.rows);});
After applying the fix and restarting, the same request produces a trace with a single PostgreSQL span, and the total duration drops accordingly.
Finding the phantom cache miss
The N+1 query was visible because it produced an obvious waterfall of spans, but some performance problems are subtler. They don't create extra spans or slow things down dramatically; they just quietly do more work than necessary on every request. The custom attributes you added to the auto-instrumented spans are what make these problems discoverable.
Create a short URL, then follow the redirect. Go to Jaeger and open the trace
for the redirect request. Then look at the shortener.cache_hit attribute on
the Redirector's request handler - /resolve/:code span:
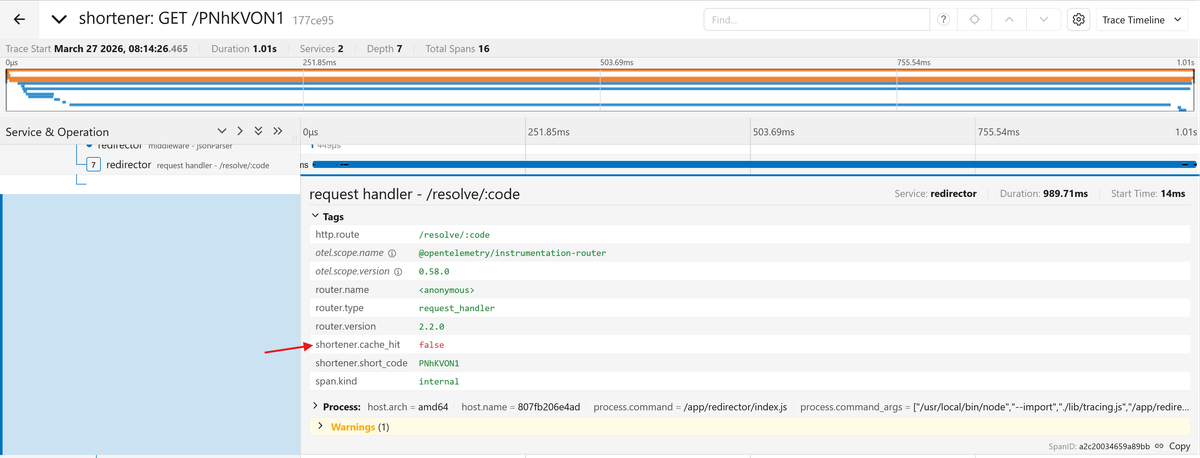
It should be true since you just created this URL and the Shortener cached it
in Redis. But the attribute reads false. Redirect the same URL again and it
now reads true:
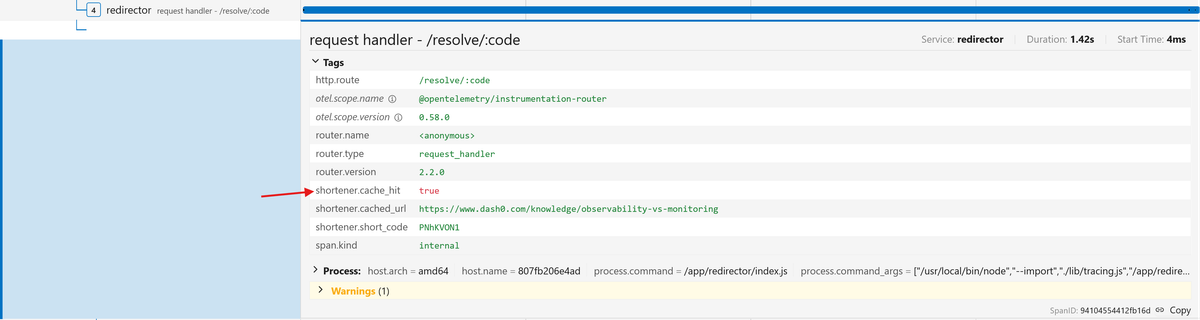
So the cache works on subsequent requests (as long as the entry hasn't expired), but the very first redirect after creation always misses, even though the Shortener wrote the cache entry moments earlier. Something is wrong between the write and the first read.
Check the Redis cache key that the Shortener writes on URL creation:
12// shortener/routes.jsawait redis.set(`url:${shortCode}`, url, { EX: 86400 });
Now check what the Redirector reads:
12// redirector/routes.jsconst cached = await redis.get(`urls:${code}`);
You should immediately spot that the problem is url: vs urls:. On the first
redirect, the Redirector reads from a key that was never written, falls back to
PostgreSQL, then writes its own cache entry under the urls: prefix.
Subsequent redirects hit that entry and appear to work fine, which is exactly why this bug is so easy to miss. The app functions correctly from the user's perspective, but every first redirect after creation pays the database cost unnecessarily, and Redis accumulates a parallel set of entries under the wrong prefix.
Fix the Redirector to use the correct key format:
1234// redirector/routes.jsconst cached = await redis.get(`url:${code}`);// ...await redis.set(`url:${code}`, originalUrl, { EX: 86400 });
After rebuilding the services, create a new short URL and visit it immediately.
The first visit should show shortener.cache_hit: true in the trace, and the
PostgreSQL SELECT query span disappears.
Neither of these problems would have been caught through logs alone as the N+1 query logged a series of successful database operations and you would have been none the wiser that they all came from a single request. The cache miss would have logged nothing at all because it wasn't an error from the application's perspective.
What tracing adds is the ability to see how operations relate to each other in
time and across services, not just whether each individual operation succeeded.
The waterfall pattern in the N+1 trace and the shortener.cache_hit: false
attribute on the first redirect are structural and contextual signals that only
exist in traces.
Beyond Jaeger: sending traces to a production backend
Jaeger is a great tool for exploring traces in development, but it only focuses on a single signal. In production, the questions you need to answer will span logs, metrics, and traces.
You might need to determine which deployment introduced a latency regression, how a slow trace relates to a spike in error logs, or what resource metrics looked like for the pod that handled a request.
Answering these questions requires a backend that treats all telemetry signals as connected parts of the same system rather than isolated data streams living in separate databases.
Dash0 is built around this idea. It's an OpenTelemetry-native observability platform, meaning its storage, query engine, and UI are designed around the OTel data model from the ground up rather than translating OTel data into a proprietary format on the way in.
Since your application already exports OpenTelemetry traces through the Collector, sending data to Dash0 is simply a configuration change. You don't need to modify your application code or SDK setup in any way.
Update your otelcol.yaml to add Dash0 as an exporter:
123456789101112exporters:otlp_http/dash0:endpoint: https://ingress.eu-west-1.aws.dash0.comheaders:Authorization: "Bearer ${DASH0_AUTH_TOKEN}"Dash0-dataset: ${DASH0_DATASET}service:pipelines:traces:receivers: [otlp]exporters: [otlp_http/dash0]
Once configured, your traces will appear in Dash0 with all attributes, error states, and cross-service context preserved, ready for querying, correlation, and alerting.
If you're running on Kubernetes, the Dash0 Operator can auto-instrument your workloads and inject the SDK and environment variables automatically, eliminating the per-service configuration overhead entirely.
Final thoughts
You started this guide with a working application and zero observability. By the end, you've added auto-instrumentation that captures every HTTP request, database query, and cache command across two services; customized span names to make traces readable at a glance; created manual spans that expose business logic the auto-instrumentation can't reach; and used the resulting traces to find two performance bugs that no amount of logging would have revealed.
Everything you've built here uses open standards. The traces export over OTLP, the attributes follow OpenTelemetry semantic conventions, and the SDK configuration is portable across backends. Switching from Jaeger to Dash0 was a Collector config change, and switching again to any other OTLP-compatible backend would be the same.
This guide samples 100% of traces, which is appropriate for local development but not for most production environments. OpenTelemetry supports several sampling strategies that can be configured through the SDK and Collector. Getting sampling right is essential for controlling costs and storage volume while still capturing the traces that matter.
For further reading, see our reference on configuring OpenTelemetry with environment variables and our guide on building telemetry pipelines with the OpenTelemetry collector.
