Last updated: February 16, 2026
W3C Trace Context Explained: Traceparent & Tracestate
Modern distributed systems are built from many small services that communicate over HTTP, gRPC, or messaging systems. When a request fails or slows down, you need to understand exactly where it went and what happened along the way. Distributed tracing gives you that visibility, but only if trace context moves reliably from one service to the next.
This is where context propagation becomes critical. If even one service fails to forward the trace headers, your end-to-end trace breaks into disconnected segments. Instead of seeing a single request flowing through your system, you'll see isolated spans with no clear relationship, defeating the purpose of tracing in the first place.
The W3C Trace Context specification defines a standard way to propagate trace identity across service boundaries and it has already achieved widespread adoption throughout the observability ecosystem.
In this article, you'll learn how the specification works, what the headers mean, and how to implement it correctly so your traces remain intact across your entire architecture.
Why trace context propagation needed a standard
Distributed tracing only works if every service that participates in a request agrees on one thing: how to identify that request.
A trace is just a collection of spans tied together by a shared identifier. If that identifier changes or disappears at any boundary, the trace fragments into multiple unrelated pieces.
Historically, context propagation was implemented through vendor-specific
proprietary headers such as X-B3-TraceId, X-Amzn-Trace-Id, and other
variants that only worked inside a single ecosystem.
But without a shared propagation standard, several things go wrong:
- A trace collected by one tool cannot be correlated with data from another.
- When a request crosses a vendor boundary, the trace identity is lost.
- Intermediaries forward traffic but drop proprietary headers.
- Platform providers cannot reliably support every custom format.
The W3C Trace Context was created to remove that ambiguity. It defines a common, vendor-neutral way to propagate trace identity so that every component in the path can forward it, regardless of which tracing backend you use.
The specification defines two HTTP headers: traceparent for core trace
identity, and tracestate for vendor-specific extensions.
Understanding the traceparent header
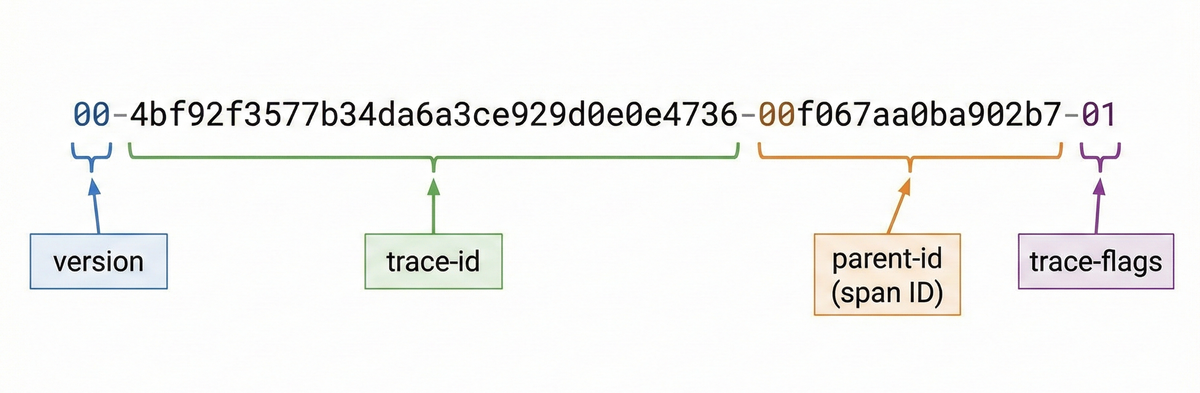
The traceparent header contains the minimal information required to connect
spans across services. It's a single string with four dash-separated fields:
12345traceparent: 00-4bf92f3577b34da6a3ce929d0e0e4736-00f067aa0ba902b7-01| | | |- trace-flags| | |- parent-id (span ID)|- trace-id|- version
Let's break it down:
-
Version: An 8-bit value indicating the format version. The current specification defines a single version
00, and versionffis reserved as invalid. -
Trace ID: A 16-byte identifier encoded as 32 lowercase hexadecimal characters that must remain constant across the entire distributed trace. The value should be globally unique and randomly generated.
-
Parent ID: An 8-byte identifier encoded as 16 lowercase hexadecimal characters. Each service generates a new parent ID for its own span while preserving the trace ID.
-
Trace flags: An 8-bit field encoded as two hexadecimal characters. The least significant bit represents the sampling decision:
01means the trace is sampled00means it's not sampled
Understanding the tracestate header
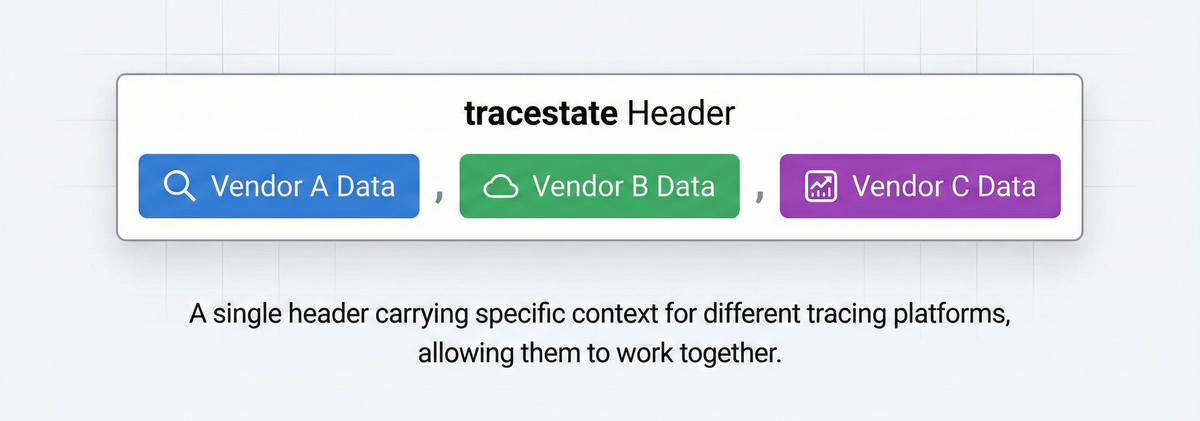
While the traceparent header defines the trace identity, the tracestate
header complements it by allowing each tracing system to carry its own
additional context alongside that identity.
In practice, you'll rarely see tracestate populated in most setups. Many
systems rely entirely on traceparent for context propagation and either do not
use tracestate at all or only use it in advanced scenarios (like multi-vendor
migrations).
When it's present, it looks like this:
1tracestate: vendor1=opaque_data,vendor2=sampling:0.1;id:xyz
The header is a comma-separated list of key-value pairs (key=value). Each key
identifies a tracing system, and each value contains opaque, vendor-defined
data. All other systems must forward these entries unchanged, even if they don't
understand their contents.
Whenever a system updates the parent-id in the traceparent header, it must
move its corresponding entry in tracestate to the front (the left).
Whenever a system adds a new entry or updates its own value, it must place that
entry at the left side of the list. This ensures the leftmost entry always
represents the system that most recently participated in the trace and updated
the traceparent parent ID.
How trace context propagation works in practice
The specification defines precise rules for parsing and mutating headers, but it helps to translate those rules into a concrete request lifecycle. When you understand what should happen at each hop, troubleshooting broken traces becomes much easier.
Scenario 1: A request enters your system
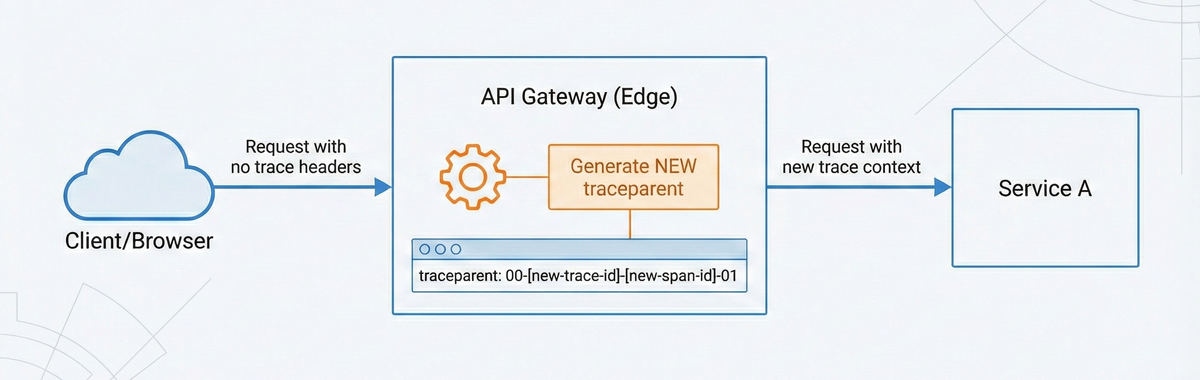
A new trace typically begins at the first component that handles an external request. This is often your API gateway, edge proxy, or load balancer, in other words, the boundary where traffic first enters your system from an external source.
If an incoming request does not contain a valid traceparent header, that
component becomes the start of a new distributed trace. This means the component
must:
- Generate a new 16-byte trace ID.
- Generate a new span ID that represents the current operation.
- Set trace flags based on sampling policy.
- Construct a valid
traceparentheader. - Optionally create a
tracestateentry if needed.
From this entry point onward, the trace ID must remain stable as the request flows through the other service components.
Scenario 2: Your service calls another service
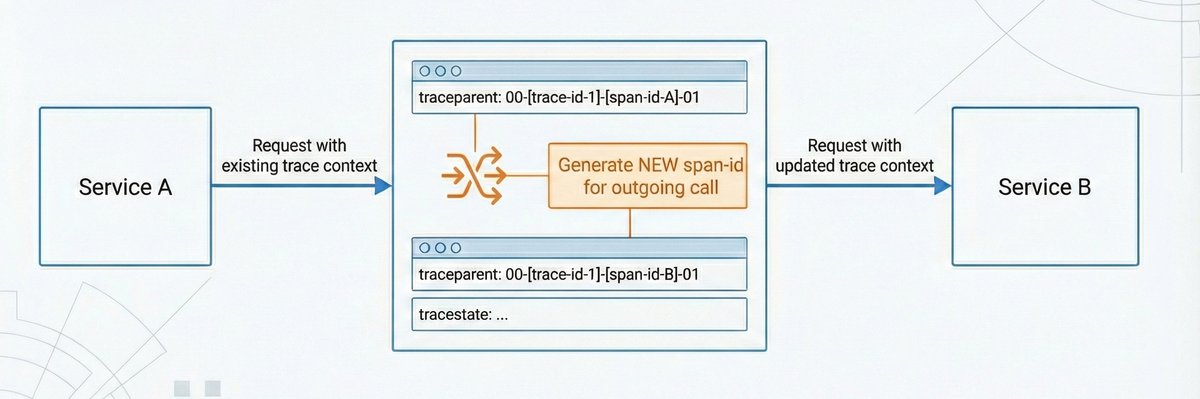
If a valid traceparent header is present, it means that the service is joining
an existing trace. Some infrastructure components may only forward traceparent
and tracestate without creating their own spans. However, any component that
performs meaningful work should typically participate in the trace.
Before making an outgoing request, the service must:
- Preserve the incoming trace ID from the incoming request.
- Generate a new parent ID for its span.
- Update the trace flags if needed.
- Maintains
tracestateentries, adding its own to the left if needed. - Inject trace context headers into the outgoing HTTP request.
Updating the parent ID is mandatory as each hop in the trace graph must have its own span identifier. The trace ID stays constant, but the parent ID must change at every boundary.
If these headers are not forwarded correctly, the downstream service will start a new trace, resulting in fragmented spans in your tracing backend.
Scenario 3: Asynchronous workflows and background jobs
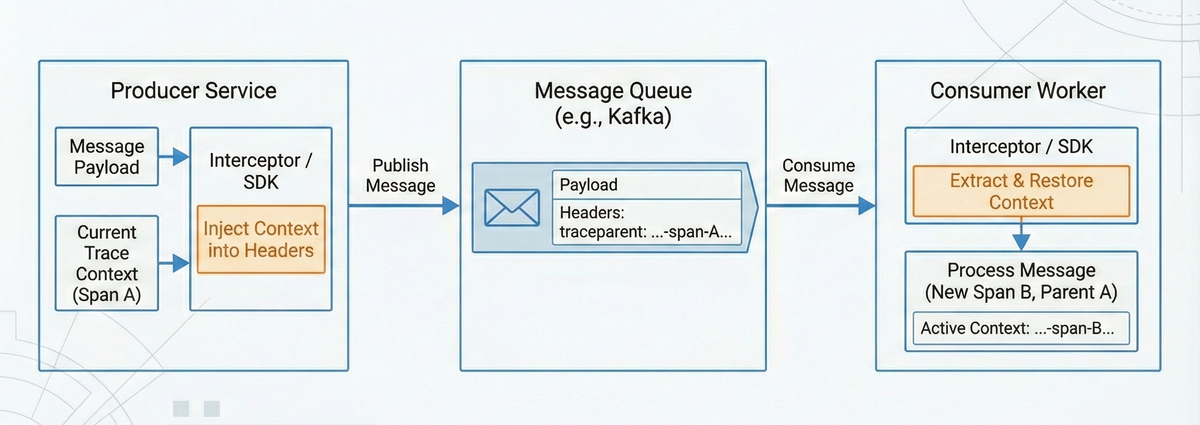
The most challenging scenario for trace context propagation involves asynchronous workflows, message queues, and background jobs where execution doesn't follow a simple request-response pattern and other transport-level mechanisms aren't available.
In these cases, relying only on transport-level headers is not enough; the trace context must travel with the work itself. This means embedding the W3C trace context directly in the message or job payload.
For example:
- Workflow engines can include
traceparentin activity requests. - Message queues can attach trace context as message headers or properties.
- Background job systems can persist trace context alongside job parameters.
- Thread handoffs can explicitly restore context before executing work.
12345678910{"metadata": {"traceparent": "00-4bf92f3577b34da6a3ce929d0e0e4736-00f067aa0ba902b7-01","tracestate": "conflux=t61rcWvJ5Yw"},"payload": {"order_id": "ORD-9921","status": "processed"}}
Since the worker won't automatically find these fields inside a JSON blob or a Protobuf message, you have to manually re-hydrate the context at the edge of your worker logic.
1234567def process_background_job(job_data):trace_header = job_data.get('metadata', {}).get('traceparent')parent_context = extract_traceparent_to_otel_context(trace_header)with tracer.start_as_current_span("worker_operation", context=parent_context):do_actual_work(job_data['payload'])
By restoring the parent context explicitly, any downstream operations are correctly attached to the original distributed trace.
The key principle is simple: if transport-level headers are unavailable or insufficient, trace context must be carried as part of the application-level payload to preserve trace continuity.
Using W3C Trace Context with OpenTelemetry
OpenTelemetry is the default vendor-neutral standard for collecting traces, metrics, and logs. For distributed tracing, it uses the W3C Trace Context as the default propagation format across languages and platforms.
In practice, this means that once a service is instrumented with an
OpenTelemetry SDK, traceparent and tracestate headers are automatically:
- Extracted from incoming requests
- Stored in the current execution context
- Injected into outgoing requests
In most cases, there's no need to manually parse or construct headers. The SDK handles propagation according to the W3C specification.
Although W3C Trace Context is the default, it can also be configured explicitly:
123456import ("go.opentelemetry.io/otel""go.opentelemetry.io/otel/propagation")otel.SetTextMapPropagator(propagation.TraceContext{})
This ensures that the service extracts and injects W3C-compliant headers for all supported transports.
When manual handling is required
There are scenarios where manual propagation becomes necessary:
- Services that are not automatically instrumented.
- Asynchronous execution contexts.
- Message queues or event-driven systems.
- Cross-process communication without HTTP.
In such cases, OpenTelemetry provides the Propagators API to explicitly extract and inject context from carrier objects such as maps, message headers, or metadata structures.
The key takeaway is that OpenTelemetry abstracts most of the complexity of W3C Trace Context. Once instrumentation is in place, propagation becomes a default behavior rather than something that must be implemented manually in every service.
Trace context level 2: what's coming
The original W3C Trace Context specification defines the traceparent and
tracestate headers and establishes the processing rules for propagation. A
newer draft, known as
Trace Context Level 2, builds on that
foundation and refines several areas of the standard.
The most notable addition is a new flag in the trace-flags field: the
random-trace-id flag. When this flag is set, it signals that the trace-id
was generated with sufficient randomness. This allows downstream systems to rely
on stronger guarantees around uniqueness, privacy, and sampling decisions.
Level 2 also expands guidance around:
- Random and globally unique
trace-idgeneration. - Placement of random bits within the trace ID.
- Interoperability with systems that use shorter internal identifiers.
- Random and unique
span-idgeneration.
These changes do not alter the overall header structure. The traceparent
format remains the same, and backward compatibility is preserved. Existing
implementations of version 00 continue to work unchanged.
At the time of writing, Trace Context Level 2 is a Candidate Recommendation Draft. That means it's still evolving and may change before becoming a full Recommendation.
For most implementations today, the current spec remains fully sufficient. Level 2 primarily strengthens randomness guarantees and clarifies best practices rather than redefining how trace context propagation works.
Final thoughts
W3C Trace Context solves a simple but critical problem: keeping trace identity intact across distributed systems.
If you operate microservices, serverless functions, or hybrid cloud systems, you need reliable context propagation. The standard format ensures that your traces survive vendor boundaries, infrastructure layers, and language differences.
With OpenTelemetry providing seamless implementation and major cloud providers, APM vendors, and open-source projects all supporting the standard, W3C Trace Context has become the standard way to implement trace propagation in modern distributed systems.
If you want to go deeper, review the official W3C specification and OpenTelemetry documentation, and test propagation across your own service boundaries under real traffic conditions.
Thanks for reading!
