Last updated: September 30, 2025
OpenTelemetry Journald Receiver: A Guide to Ingesting Systemd Logs
If you're running applications on a modern Linux system,
the systemd journal
is probably doing more work behind the scenes than you realize. It serves as the
central log service, capturing everything from kernel messages and boot-time
errors to the stdout and stderr of all your systemd services.
The OpenTelemetry Collector's journald receiver provides a direct pipeline into this valuable stream of system and application telemetry.
The official documentation covers configuration, but it often leaves out the bigger picture: why this receiver matters and how to make the most of it. That's what this guide is for. We'll look at real-world scenarios, common permission pitfalls, and ways to turn raw journal entries into structured, actionable observability data.
Let's dive in!
What is systemd-journald and why use this receiver?
Before looking at configuration, it helps to understand what sets
systemd-journald apart from earlier logging systems.
Unlike plain-text log files such as /var/log/syslog, journald stores events
in a structured binary format. Each entry is a collection of key–value pairs
that capture both the message and its surrounding context.
Unlike plain-text, file-based logging (e.g., /var/log/syslog), journald
stores events in a structured, binary format. Instead of simple log lines, each
entry is a bundle of key–value pairs that capture both the message and its
context.
By default, journald enriches every log entry with metadata such as:
_SYSTEMD_UNIT: The service orsystemdtarget that generated the log._PID: The process ID of the logging process._UID: The user ID of the logging process._HOSTNAME: The host where the log originated.PRIORITY: The standard syslog severity level (e.g.,3for error,6for info).- And many more.
This built-in metadata makes journald a powerful source of observability data.
Instead of parsing unstructured text and trying to extract meaning, you start
with structured context out of the box.
To make the most of it, though, you still need to align these fields with the OpenTelemetry log data model.
By applying transformations at ingestion, you can normalize the data, promote key fields into top-level attributes, and ensure your logs integrate cleanly with traces and metrics.
In short, if you're running on Linux, the journald receiver is the most
direct way to get logs into your OpenTelemetry pipeline.
Quick start: tailing your system logs
Let's start by getting your Systemd logs flowing through the OpenTelemetry
Collector. We'll begin by tailing recent journal entries so you can confirm the
journald receiver is working.
First, create a minimal otelcol.yaml for your Collector:
1234567891011121314# otelcol.yamlreceivers:journald:directory: /var/log/journal # defaults to /run/log/journal or /run/journalexporters:debug:verbosity: detailedservice:pipelines:logs:receivers: [journald]exporters: [debug]
This configuration wires the journald receiver directly to a
debug exporter.
With no filters, every log entry available to the Collector process is ingested,
and because the receiver defaults to "tail mode", you'll only see new entries as
they arrive.
The debug exporter prints them to stdout with full verbosity, which means
you'll get the raw message as well as all the structured metadata
(_SYSTEMD_UNIT, _PID, PRIORITY, etc.).
To run the journald receiver in Docker, you need to address two main
challenges: the
official Collector image
lacks the necessary journalctl binary, and the container needs access to the
host machine's journal logs. This involves creating a custom Docker image and
running it with the correct volume mounts.
Here's a Dockerfile you can use:
1234567891011121314151617181920212223242526FROM debian:13-slimARG OTEL_VERSION=0.135.0RUN apt-get update && \apt-get install -y systemd wget && \apt-get clean && \rm -rf /var/lib/apt/lists/*RUN wget "https://github.com/open-telemetry/opentelemetry-collector-releases/releases/download/v${OTEL_VERSION}/otelcol-contrib_${OTEL_VERSION}_linux_amd64.tar.gz" && \tar -xzf "otelcol-contrib_${OTEL_VERSION}_linux_amd64.tar.gz" && \mv "otelcol-contrib" /usr/local/bin/otelcol-contrib && \rm "otelcol-contrib_${OTEL_VERSION}_linux_amd64.tar.gz"RUN chmod +x /usr/local/bin/otelcol-contribRUN groupadd --system --gid 10001 otel && \useradd --system --uid 10001 --gid otel otelRUN usermod -aG systemd-journal otelUSER otelENTRYPOINT ["/usr/local/bin/otelcol-contrib"]CMD ["--config", "/etc/otelcol-contrib/config.yaml"]
This Dockerfile builds a container image that runs the OpenTelemetry Collector with access to systemd journal logs. It installs the necessary dependencies, downloads the requested version of otelcol-contrib, and places it in /usr/local/bin with the correct permissions.
To run securely, the image creates a dedicated non-root otel user, adds it to the systemd-journal group so it can read host logs, and switches to that user. The container starts by executing the Collector binary and expects a configuration file to be mounted at /etc/otelcol-contrib/config.yaml.
When you run the container, you must mount your Collector configuration file and
the host's journal directory into the container so that the journald receiver
can access it.
Here's a docker-compose.yml file that does just that:
12345678910# docker-compose.ymlservices:otelcol:build: .container_name: otelcolrestart: unless-stoppedvolumes:- ./otelcol.yaml:/etc/otelcol-contrib/config.yaml- /var/log/journal:/var/log/journal:rocommand: ["--config=/etc/otelcol-contrib/config.yaml"]
With your Dockerfile, otelcol.yaml, and docker-compose.yml files in the
same directory, you can start the Collector with a single command:
1docker compose up -d
This basic pipeline is for confirming that the Collector has permission to read the journal and helping you inspect what data is available before you start filtering, enriching, or forwarding logs to a backend.
Once the Collector is up and running, you can check the logs with:
1docker compose logs otelcol -f
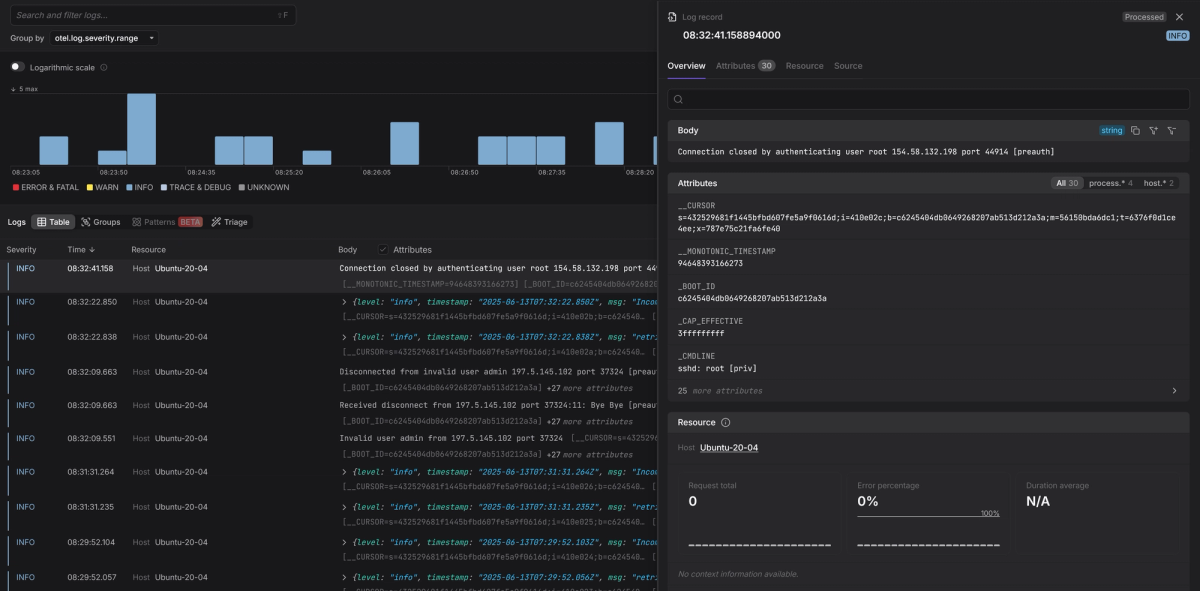
You should immediately see logs from your system printed to the console. Here's what a single record looks like:
123456789LogRecord #0ObservedTimestamp: 2025-09-24 08:13:57.494266297 +0000 UTCTimestamp: 2025-09-24 08:12:37.178081 +0000 UTCSeverityText:SeverityNumber: Unspecified(0)Body: Map({"MESSAGE":"Received disconnect from 180.101.88.228 port 11349:11: [preauth]","PRIORITY":"6","SYSLOG_IDENTIFIER":"sshd","_BOOT_ID":"0fb705b9f6e34383ab5dcf01f01cc301","_CAP_EFFECTIVE":"0","_COMM":"cat","_GID":"1000","_HOSTNAME":"falcon","_MACHINE_ID":"4a3dc42bf0564d50807d1553f485552a","_PID":"19983","_RUNTIME_SCOPE":"system","_STREAM_ID":"6073693a010545748e7bb93cf40d290e","_TRANSPORT":"stdout","_UID":"1000","__CURSOR":"s=e4e334c7ca514019a5be6442d7ecd6f9;i=e72f;b=0fb705b9f6e34383ab5dcf01f01cc301;m=2eab6a9e6e;t=63f879d94dee1;x=bfb32709d845fa9e","__MONOTONIC_TIMESTAMP":"200444386926","__SEQNUM":"59183","__SEQNUM_ID":"e4e334c7ca514019a5be6442d7ecd6f9"})Trace ID:Span ID:Flags: 0
This output shows that the receiver is working correctly. By default, it has
captured a complete journal entry and placed all of its structured fields as
key-value pairs inside a Map within the log's Body.
You can see useful context directly in the map, such as the service name
(_SYSTEMD_UNIT: systemd-resolved.service) and the actual log line
(MESSAGE: Clock change detected. Flushing caches.).
One thing you'll notice, though, is that all of these fields are sitting inside
the Body map. The top-level Attributes field is missing, and the
SeverityNumber is unset.
In the next section, we'll look at how to further refine this data so that they are fully compliant with the OpenTelemetry log data model and semantic conventions.
Transforming logs with operators
The journald receiver's main role is to get raw log entries from the system
journal into the Collector pipeline. Often, these entries often need further
parsing and restructuring to fully align with the OpenTelemetry model.
To handle this, the receiver supports Stanza operators that can transform logs at ingestion time. Operators can move fields, flatten maps, parse messages, or drop unneeded data before the logs move downstream.
From the previous section, you saw that the structured journald metadata is
all buried inside the Body map. To make this data usable, the first step is to
move it into Attributes:
1234567receivers:journald:directory: /var/log/journaloperators:- type: movefrom: bodyto: attributes["body"]
Since move cannot write directly to the attributes root, we place the
content under the body subfield. At this stage, everything sits under
Attributes.body:
12345678910ObservedTimestamp: 2025-09-24 08:20:56.515103556 +0000 UTCTimestamp: 2025-09-24 08:10:47.894808 +0000 UTCSeverityText:SeverityNumber: Unspecified(0)Body: Empty()Attributes:-> body: Map({"MESSAGE":"Received disconnect from 180.101.88.228 port 11349:11: [preauth]","PRIORITY":"6","SYSLOG_IDENTIFIER":"sshd","_BOOT_ID":"0fb705b9f6e34383ab5dcf01f01cc301","_COMM":"cat","_GID":"1000","_HOSTNAME":"falcon","_MACHINE_ID":"4a3dc42bf0564d50807d1553f485552a","_PID":"19616","_RUNTIME_SCOPE":"system","_STREAM_ID":"f4dc341a347d44d58c3cee95fa362d92","_TRANSPORT":"stdout","_UID":"1000","__CURSOR":"s=e4e334c7ca514019a5be6442d7ecd6f9;i=e707;b=0fb705b9f6e34383ab5dcf01f01cc301;m=2ea480e314;t=63f8797115718;x=67d491c4912333da","__MONOTONIC_TIMESTAMP":"200328405780","__SEQNUM":"59143","__SEQNUM_ID":"e4e334c7ca514019a5be6442d7ecd6f9"})Trace ID:Span ID:Flags: 0
Next,
flatten
the Attributes.body map so that each journal field becomes a direct child of
Attributes:
123456789receivers:journald:directory: /var/log/journaloperators:- type: movefrom: bodyto: attributes["body"]- type: flattenfield: attributes["body"]
The result is that all the journal fields are now directly nested under
Attributes:
123456789101112131415161718192021222324252627ObservedTimestamp: 2025-09-24 08:22:59.057886367 +0000 UTCTimestamp: 2025-09-24 08:12:37.178081 +0000 UTCSeverityText:SeverityNumber: Unspecified(0)Body: Empty()Attributes:-> _RUNTIME_SCOPE: Str(system)-> __CURSOR: Str(s=e4e334c7ca514019a5be6442d7ecd6f9;i=e72f;b=0fb705b9f6e34383ab5dcf01f01cc301;m=2eab6a9e6e;t=63f879d94dee1;x=bfb32709d845fa9e)-> PRIORITY: Str(6)-> __SEQNUM_ID: Str(e4e334c7ca514019a5be6442d7ecd6f9)-> MESSAGE: Str(Received disconnect from 180.101.88.228 port 11349:11: [preauth])-> _MACHINE_ID: Str(4a3dc42bf0564d50807d1553f485552a)-> __MONOTONIC_TIMESTAMP: Str(200444386926)-> _UID: Str(1000)-> __SEQNUM: Str(59183)-> _COMM: Str(cat)-> _TRANSPORT: Str(stdout)-> _CAP_EFFECTIVE: Str(0)-> _GID: Str(1000)-> SYSLOG_IDENTIFIER: Str(sshd)-> _BOOT_ID: Str(0fb705b9f6e34383ab5dcf01f01cc301)-> _PID: Str(19983)-> _STREAM_ID: Str(6073693a010545748e7bb93cf40d290e)-> _HOSTNAME: Str(falcon)Trace ID:Span ID:Flags: 0
The Body field is still empty, though, which isn't very useful if you want the
actual log message visible in queries. To fix this, move the MESSAGE field
from Attributes back into the Body:
123456789101112receivers:journald:directory: /var/log/journaloperators:- type: movefrom: bodyto: attributes["body"]- type: flattenfield: attributes["body"]- type: movefrom: attributes["MESSAGE"]to: body
At this point the Body contains the original log line, while all the
supporting metadata remains in Attributes:
123456ObservedTimestamp: 2025-09-24 08:24:39.676402302 +0000 UTCTimestamp: 2025-09-24 08:12:37.178081 +0000 UTCSeverityText:SeverityNumber: Unspecified(0)Body: Str(Received disconnect from 180.101.88.228 port 11349:11: [preauth]). . .
You can go farther by using the
regex_parser operator
to pull out the client IP and port from the SSH disconnect message and add them
to the Attributes:
1234567891011121314151617receivers:journald:directory: /var/log/journaloperators:- type: movefrom: bodyto: attributes["body"]- type: flattenfield: attributes["body"]- type: movefrom: attributes["MESSAGE"]to: body- type: regex_parserparse_from: bodyregex:'Received disconnect from (?P<client_address>[\d.]+) port(?P<client_port>\d+)'
You will observe the client_address and client_port fields in the
Attributes field as follows:
1234Attributes:-> client_address: Str(180.101.88.228)-> client_port: Str(11349). . .
From this point, you can continue using other operators or the OpenTelemetry Transform Language (OTTL) for more advanced transformations. Common next steps include:
- Rename
client_addresstoclient.addressandclient_porttoclient.portto conform to OpenTelemetry semantic conventions. - Map the numeric syslog
PRIORITYto proper OpenTelemetry severity fields. - Map the host and process context to their respective resource attributes, then drop noisy keys you no longer need.
You can see a practical example of how this looks in practice here.
Configuring the journald receiver
The journald receiver is designed to work well out of the box for common use
cases, but knowing its defaults helps you avoid surprises and ensures you're
collecting the right data consistently.
Choosing a starting position
By default, the start_at parameter is set to end. When the Collector starts,
the receiver only reads new logs written to the journal from that moment onward.
Historical logs already in the journal are skipped.
If you want to ingest all existing logs on the first run, change this setting to
beginning:
123receivers:journald:start_at: beginning
Enabling cursor persistence
The receiver tracks its place in the journal with a cursor. By default, this
cursor is stored in memory only so if the process restarts, it loses that
position and resumes at the end of the journal (assuming start_at is set to
end). Any logs written to the journal while the Collector was down are lost
permanently.
In production, it's best to configure a storage extension like
file_storage.
This ensures the cursor is written to disk and survives restarts, allowing the
receiver to pick up exactly where it left off:
12345678910receivers:journald:storage: file_storage/journaldextensions:file_storage/journald:directory: .service:extensions: [file_storage/journald]
Understanding default filters
By default, journalctl filters such as units, matches, and identifiers
are unset. With no filters, the receiver collects logs from all systemd units,
which is rarely what you want in practice.
The only filter applied by default is priority, which is set to info to
exclude lower-level logs like debug messages.
123receivers:journald:priority: info # the default
Let's look at filtering in more detail next.
Filtering journald logs
Tailing the entire journal is rarely useful and often wasteful. The journald
receiver provides the ability to query the journal for specific logs before they
ever enter the pipeline. This approach is far more efficient than ingesting
everything and
filtering later with a processor.
Behind the scenes, the receiver builds a journalctl command. Each
configuration option maps directly to a journalctl flag, giving you
fine-grained control over what gets collected.
1. Filtering by service
The most common use case is targeting logs from specific services you're
responsible for. The units parameter accepts a list of systemd units to
monitor.
For example, you can collect logs only from nginx.service and docker.service
with the following configuration:
12345receivers:journald:units:- nginx.service- docker.service
2. Filtering by priority
In many cases you only want to see problems rather than routine informational messages. The priority parameter lets you narrow collection to a chosen severity level and everything above it.
For example, setting the priority to warning ensures that only warnings,
errors, critical alerts, and emergency messages are pulled into the pipeline:
123receivers:journald:priority: warning
3. Filtering with grep
The grep option lets you narrow results to only those log entries whose
MESSAGE field matches a given regular expression pattern. This is useful for
quickly isolating events that contain specific keywords.
For example, to capture only logs where the message contains the text
OOMKilled, use:
123receivers:journald:grep: OOMKilled
This translates into a journalctl -g OOMKilled command behind the scenes. You
can supply any valid regular expression, which makes it easy to search for
patterns like error codes, substrings of log messages, or application-specific
markers.
4. Filtering with dmesg
If you want to focus exclusively on low-level system events such as hardware
errors, driver logs, or kernel panics, use the dmesg option. Enabling it adds
the _TRANSPORT=kernel filter and limits output to logs from the current boot.
123receivers:journald:dmesg: true
This effectively runs journalctl -b -k, ensuring that you only see entries
from the kernel ring buffer. You can build a highly focused view of critical
system-level events by combining with other filters like priority.
5. Filtering with identifiers
Every journal entry includes a SYSLOG_IDENTIFIER field, which typically
records the name of the process that wrote the log. This is often different from
the systemd unit name, and can be a useful way to filter when multiple
processes share the same unit or when you care about a specific binary's output.
For example, you might want to capture only logs produced by the CRON process,
regardless of which unit invoked it:
1234receivers:journald:identifiers:- CRON
If you provide multiple identifiers, they are treated as an OR condition:
12345receivers:journald:identifiers:- CRON- kernel
In this case, the receiver collects logs generated by either CRON or kernel.
Using identifiers is handy when a single unit manages multiple processes, or when you want to isolate output from a daemon without pulling in everything from its parent service.
6. Filtering on journal fields
For more complex scenarios, the matches option allows you to filter on any
field in a journal entry. This gives you fine-grained control when you need to
build advanced queries. Each item in the matches list acts as an OR
condition, while the key–value pairs within a single item act as AND
conditions.
For instance, if you want to capture only the logs from myapp.service that
were generated by user ID 1001, you can combine both fields in the same match:
123456receivers:journald:matches:# This single item means: _SYSTEMD_UNIT=myapp.service AND _UID=1001- _SYSTEMD_UNIT: myapp.service_UID: "1001"
In this configuration, both conditions must be true for a log to be collected.
You can also combine separate items in the list to express OR logic. For
instance, if the goal is to collect all logs from either sshd.service or
cron.service, the configuration would look like this:
12345receivers:journald:matches:- _SYSTEMD_UNIT: sshd.service- _SYSTEMD_UNIT: cron.service
To discover which fields are available on your system and their possible values, check out our journalctl guide.
7. Combining multiple filters
When you need more than one filter, the journald receiver lets you layer them
together in a logical way. The rules are simple:
- Different filtering options are combined with
ANDlogic. - Multiple values within the same option are combined with
ORlogic.
Let's look at an example:
1234567receivers:journald:priority: warningmatches:- _SYSTEMD_UNIT: containerd.service- _SYSTEMD_UNIT: kubelet.servicegrep: failed|error
This configuration results in a journalctl invocation similar to:
123journalctl --priority=warning \--unit=kubelet.service --unit=containerd.service \-g 'failed|error'
The logs returned will satisfy all of these conditions:
- The log priority is
warningor higher. - The
_SYSTEMD_UNITis eitherkubelet.serviceorcontainerd.service. - The
MESSAGEfield contains the string "failed" or "error" (case insensitive).
By combining filters in this way, you can zero in on the exact events you care about while leaving the rest of the noise behind.
Final thoughts
The journald receiver is an essential component for any observability strategy
on Linux. By tapping directly into the system’s core logging service, you'll get
deep visibility into the health and behavior of both hosts and services. With
the right filtering and deployment setup, you can build a logging pipeline that
is efficient, reliable, and rich with context.
Once your logs are structured and flowing, the natural next step is to send them to an OpenTelemetry-native platform such as Dash0. There, you can correlate logs with traces and metrics to see the complete story of your system’s behavior and performance.
Thanks for reading!
