Last updated: August 9, 2025
Mastering the OpenTelemetry Redaction Processor
Redacting sensitive data in your observability pipeline is essential for both security and compliance. If you're not careful, your logs, metrics, and traces can unintentionally expose PII, credentials, and other confidential details.
The OpenTelemetry redaction processor helps you prevent this by sanitizing telemetry data directly in the Collector. It supports removing disallowed attributes and masking sensitive values based on customizable rules.
This guide will provide a practical overview of how to configure and use the
redaction processor to keep your data secure.
Let's get started!
When to use the redaction processor
The redaction processor is your primary tool for data sanitization in an
OpenTelemetry pipeline. It excels at preventing sensitive information from
reaching your observability backend by either removing unapproved attributes
entirely or masking sensitive data within approved attributes.
Some common use cases include:
- Scrubbing PII like names, email addresses, or IP addresses to meet GDPR or CCPA requirements.
- Removing or obfuscating API keys, passwords, tokens, and other secrets that may accidentally get captured.
- Blocking or anonymizing internal codes, customer IDs, and other proprietary info before transmission.
Quick start: enabling the redaction processor
To use the redaction processor, you must declare it in the processors
section of your Collector configuration and add it to a pipeline. It works for
spans, logs, and metric datapoint attributes:
123456789101112131415161718processors:redaction:# Your redaction rules will go hereservice:pipelines:traces:receivers: [otlp]processors: [redaction] # Apply to tracesexporters: [debug]metrics:receivers: [otlp]processors: [redaction] # Apply to metricsexporters: [debug]logs:receivers: [otlp]processors: [redaction] # Apply to logsexporters: [debug]
Note: Ensure that you're using the Collector's Contrib distribution or any other distribution that contains the redaction processor component before proceeding.
Once you've enabled the redaction processor, let's look at some common patterns you can adopt to secure your telemetry data.
1. Allowing only pre-approved attributes (allowlisting)
By default, the redaction processor operates in a "fail-closed" mode where all
attributes are excluded. If you define an allowed_keys list, then only
attribute keys not on that list are completely removed.
This is the most secure approach, as it ensures only explicitly approved data gets through. Let's say you only want to keep a few specific, safe attributes on your spans such as:
12345678processors:redaction:# Only attributes with these keys will be kept. All others are dropped.allowed_keys:- http.request.method- http.route- http.response.status_code- service.name
Before allowlisting:
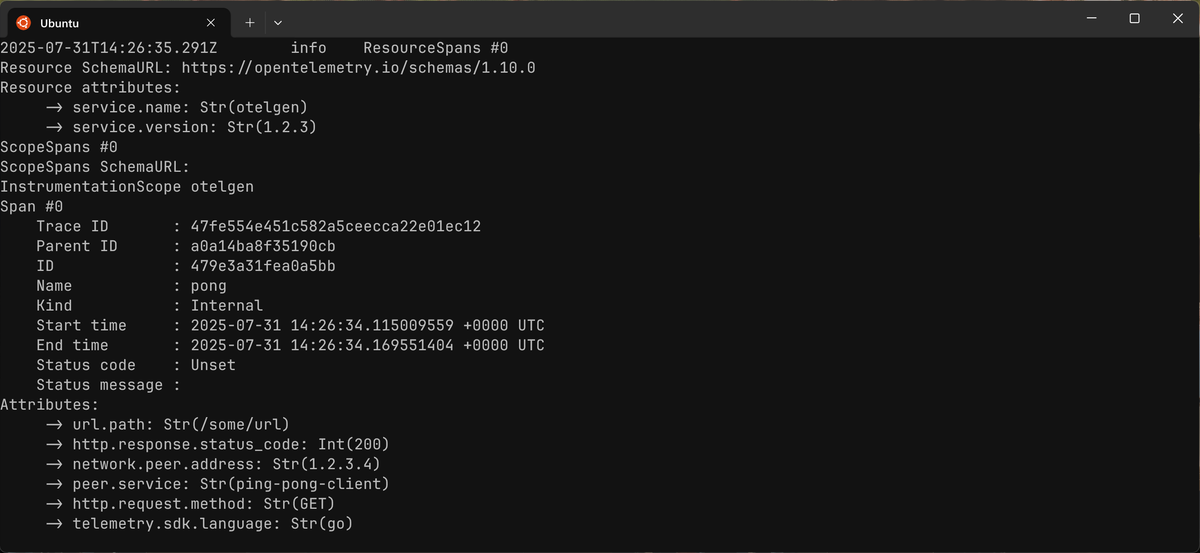
After allowlisting:
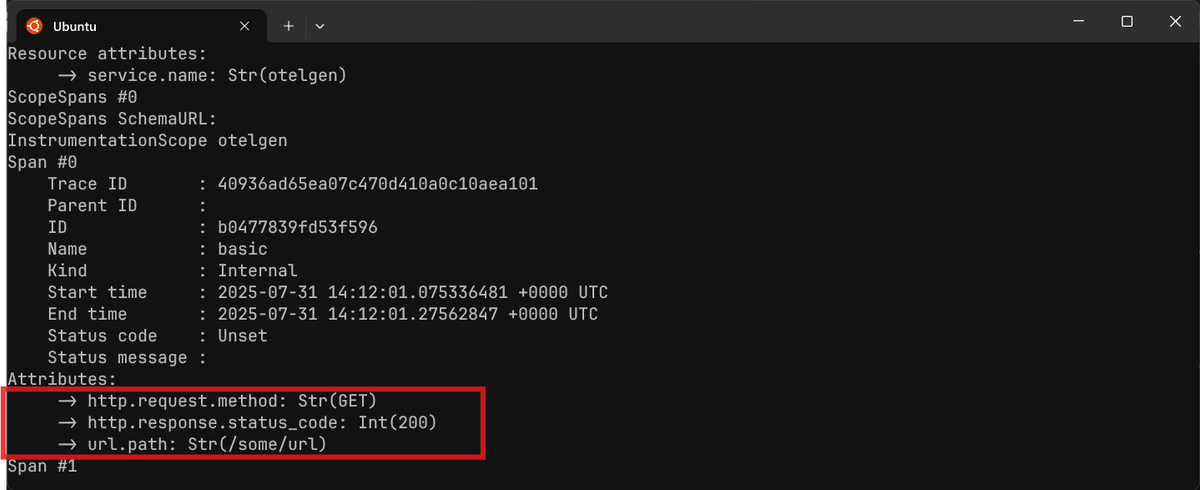
2. Removing specific attributes (blocklisting)
A common requirement is to implement a "blocklist" or "denylist" for attributes. This means a "fail-open" model where you allow most attributes to pass through but explicitly remove a few specific ones known to contain sensitive data.
The redaction processor is not the right tool for this job as its design caters only to implementing an allowlist or masking specific attributes. It does not have a function to delete attributes based on a blocklist.
For the specific use case of deleting attributes, the correct tool is the attributes processor which provides a delete action precisely for this purpose.
3. Masking sensitive data with pattern detection
Masking is the process of replacing a sensitive value (or part of it) with a
placeholder like ***. This is useful when you want to keep the attribute key
but hide the potentially sensitive information it contains.
To achieve this, you'll need to use use either blocked_key_patterns or
blocked_values to specify the masking strategy.
Masking based on value patterns (blocked_values)
The most common use case is masking values that match a regular expression. The
blocked_values option applies to any attribute key that has passed the
allowlist filter (usually by setting allow_all_keys: true).
Here’s how you could mask credit card numbers that might appear in any allowed attribute:
1234567processors:redaction:allow_all_keys: true # Let's assume we want to check all attributesblocked_values:# This regex detects Visa, Mastercard, and American Express numbers,# even when they include spaces or dashes as separators.- \b(?:4[0-9]{3}|5[1-5][0-9]{2}|3[47][0-9]{2})[ -]?([0-9]{4})[ -]?([0-9]{4})[ -]?([0-9]{4})\b
If a log has a log.body.original attribute whose value is
user paid with 4111222233334444, , the resulting output will be
log.body.original: "user paid with ****".
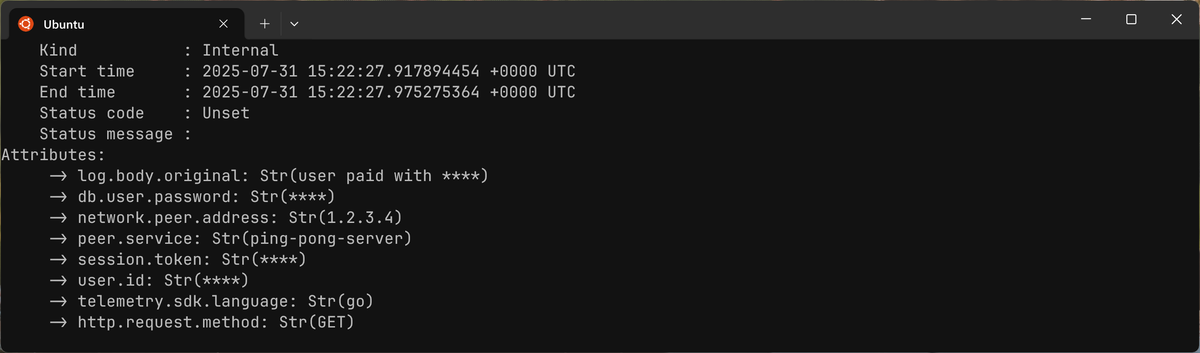
Masking based on key patterns (blocked_key_patterns)
Instead of matching the value, you can also mask the entire value of any attribute whose key matches a regex pattern. This is an alternative to deleting the attribute entirely with a blocklist:
123456789processors:redaction:# Allow all attributes to pass through by defaultallow_all_keys: true# Mask any attribute key that matches these regex patternsblocked_key_patterns:- user.id- session.token- .*password.* # Catches any key containing 'password'
With this configuration, attributes like http.request.method or url.path
will pass through untouched, while attributes matching the specified patterns
are all masked:
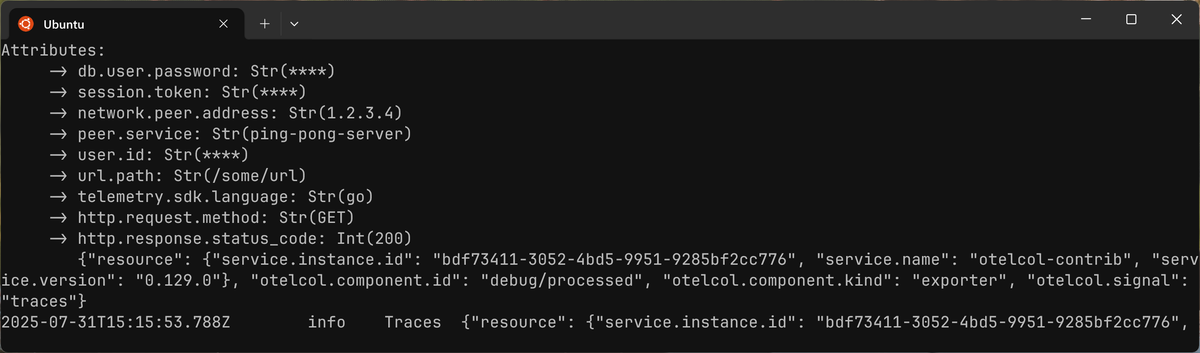
This method is convenient when you have a large number of attributes and only need to redact a small, well-defined subset. However, it carries more risk, as a new, sensitive attribute could be added to your telemetry and accidentally slip through if it doesn't match a blocking rule.
4. Bypassing redaction with ignored_keys
If you have an attribute that you know is always safe, you can use
ignored_keys to ensure it is never removed or masked. This option acts as a
universal "pass-through" by taking precedence over all other rules, including
allowed_keys and any value-blocking patterns.
For example, consider a configuration where the internal.tracking.id attribute
is added to the ignored_keys list:
12345678processors:redaction:# Only url.path is explicitly allowed...allowed_keys:- url.path# BUT, internal.tracking.id is ignored, so it will also be kept.ignored_keys:- internal.tracking.id
In a scenario where a span arrives with the url.path,
http.response.status_code, and internal.tracking.id attributes:
url.pathis kept because it's inallowed_keys. It then proceeds to the next stage, where its value may still be masked if it matches a blocking rule.http.response.status_codeis removed because it is on neither theallowed_keysnor theignored_keyslist.internal.tracking.idis kept without modification because it is on theignored_keyslist, which bypasses all other removal and masking rules.
5. Creating masking exceptions with allowed_values
The allowed_values setting lets you create exceptions to your
blocked_key_patterns or blocked_values rules. It's perfect for situations
where a broad blocking pattern, like one for all email addresses, needs to be
relaxed to permit specific cases.
When specified, the processor first checks an attribute's value against the
allowed_values patterns before checking against the blocking rules. If a value
matches a pattern in allowed_values, it is permitted, and no blocking rules
are applied.
For example, to block all external emails while allowing internal ones, you can use:
123456789processors:redaction:allow_all_keys: true# Block anything that looks like an emailblocked_values:- '[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}' # RFC 5322-ish# BUT, allow values that end in @my-safe-domain.comallowed_values:- '.+@my-safe-domain\.com'
With this configuration:
- A value like
dev.user@my-safe-domain.commatches theallowed_valuesrule, so it is left unmodified. - A value like
jane.doe@example.comdoes not matchallowed_values, so it's then checked againstblocked_values. Since it matches the general email pattern, it is subsequently masked.
6. Anonymizing attributes for with hashing
Masking a value with **** destroys its uniqueness and makes it impossible to
group or count by that attribute. If you need to obscure a value while
preserving the ability to perform some grouping or analysis, you should use
hashing instead.
The hash_function setting allows you to replace a blocked value with its hash
(md5, sha1, or sha3 to preserve its cardinality without exposing the
original data.
1234567processors:redaction:allow_all_keys: trueblocked_key_patterns:- user.email# Hash the value of any key named "user.email"hash_function: sha3
Now, the user.email attribute will be transformed to its SHA3 hash:
Before:
1user.email: john.doe@example.com
After:
1user.email: 834d1654133366cef4d81e81a7099f413b1b85b9fc9dd62140491303dec56532
Note that the redaction processor only supports unsalted hashing at the time
of writing which means hashed values could be vulnerable to
rainbow table attacks. To prevent
this, you can use the
transform processor
to apply a salted hash instead.
Verifying your redaction rules
How do you know your redaction rules are working as expected? When testing,
ensure the summary: debug setting is present so that you'll see the redacted
key name and count.
123processors:redaction:summary: debug
Depending on your redaction strategy, you'll see at least one or all of the following attributes:
redaction.masked.keys: Lists the attributes that were masked.redaction.masked.count: Counts the number of masked attributes.redaction.redacted.keys: Lists the attributes that were redacted.redaction.redacted.count: Counts the number of redacted attributes.
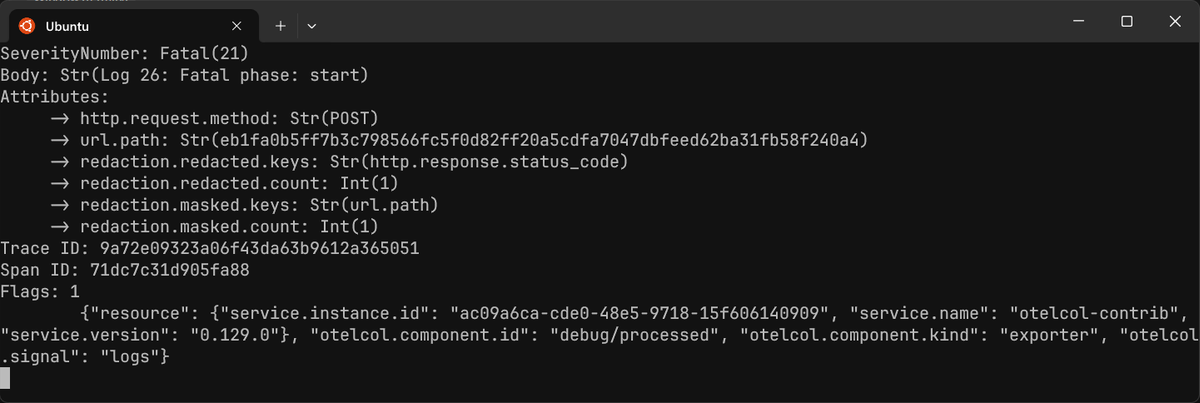
Ensure to set summary: silent in your production configuration to avoid
leaking information about what you're redacting.
Redaction processor tips and best practices
-
Fail-closed is safest: When possible, prefer using a strict
allowed_keyslist overallow_all_keys: trueas this prevents new, unvetted attributes from leaking sensitive data inadvertently. It also drastically reduces the number of attributes that need to be checked against yourblocked_valuesregex patterns which is a win for performance. -
Filter first, then redact: Always place filtering processors before the redaction processor. There is no point wasting CPU cycles redacting data that you are just going to drop anyway.
yaml12processors: [filter, redaction, batch] # Good ✅processors: [redaction, filter, batch] # Bad ❌ -
Be specific with regular expressions: When possible, avoid using broad, inefficient regex patterns like
.*sensitive-data.*. Use more specific patterns and anchor them with^(start of string) and$(end of string) instead. -
Watch for performance impact: Be mindful that very complex regular expressions can impact Collector performance so ensure to keep tabs on your collector’s performance metrics accordingly.
Final thoughts
The redaction processor is an indispensable component for building secure and
compliant observability pipelines.
By mastering its capabilities, you can confidently ensure that sensitive information is scrubbed from all your telemetry before it becomes a liability.
Once your data is cleaned and anonymized, you can send it to an OpenTelemetry-native platform like Dash0 knowing it's safe, secure, and ready to be transformed into actionable insights.
