Last updated: July 14, 2026
RED Metrics
"RED Metrics" is a framework for monitoring the health of request-driven services using three signals: Requests, Errors, and Duration.
Background
Introduced by Tom Wilkie in 2015 at Weaveworks, RED shifts the focus of monitoring from infrastructure to the experience of service consumers. Where the older USE method (Utilisation, Saturation, Errors) asks "is my infrastructure healthy?", RED asks "is my service serving users well?".
Each signal points to a different class of problem. A spike in Requests with stable Errors and Duration suggests healthy growth. A spike in Errors alone points to a bug or dependency failure. A spike in Duration with stable Requests and Errors suggests a performance regression.
RED is service-agnostic — the same three signals apply equally to an HTTP API, a gRPC service, a message queue consumer, or a database query handler, making it a natural fit for microservices architectures.
The Three Signals
| Signal | Question it answers | Typical unit |
|---|---|---|
| Request | How many requests per second is this service handling? | Requests/s |
| Errors | What fraction of those requests are failing? | Error rate (%) |
| Duration | How long are requests taking? | Latency (ms), as percentiles |
Relationship to Other Methodologies
RED is complementary to other observability frameworks rather than a replacement for them.
| Method | Signals | Best for |
|---|---|---|
| RED | Rate, Errors, Duration | Request-driven services |
| USE | Utilisation, Saturation, Errors | Infrastructure resources (CPU, disk, network) |
| Four Golden Signals | Latency, Traffic, Errors, Saturation | Full-stack observability (RED + saturation) |
Google's Four Golden Signals, from the Site Reliability Engineering book, are essentially RED with saturation added. When a RED alert fires, USE metrics on the underlying infrastructure help determine whether the root cause is a service-level issue or a resource constraint.
How Dash0 Helps with RED Metrics
Dash0 makes RED metrics actionable through automatic correlation and unified resource views.
-
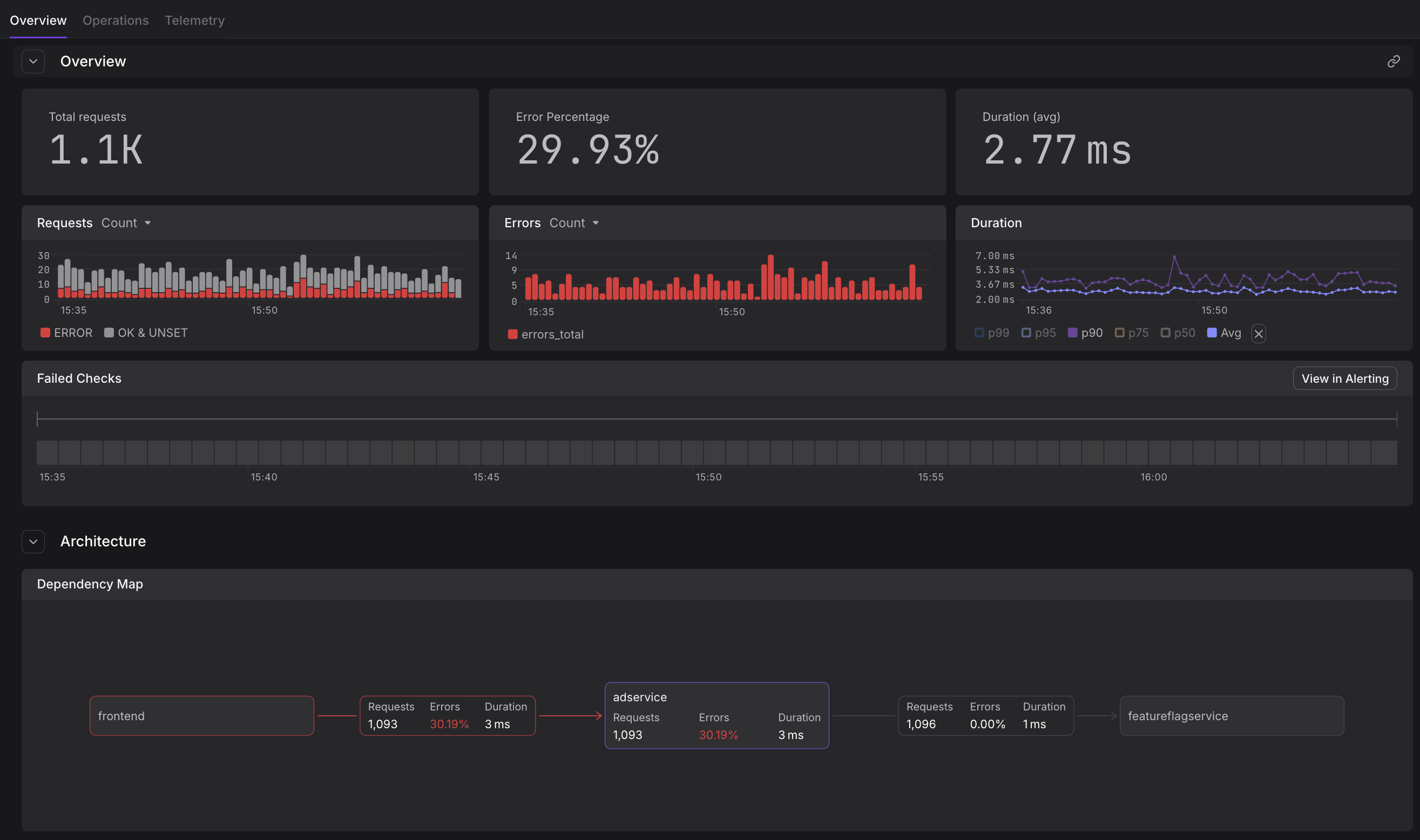
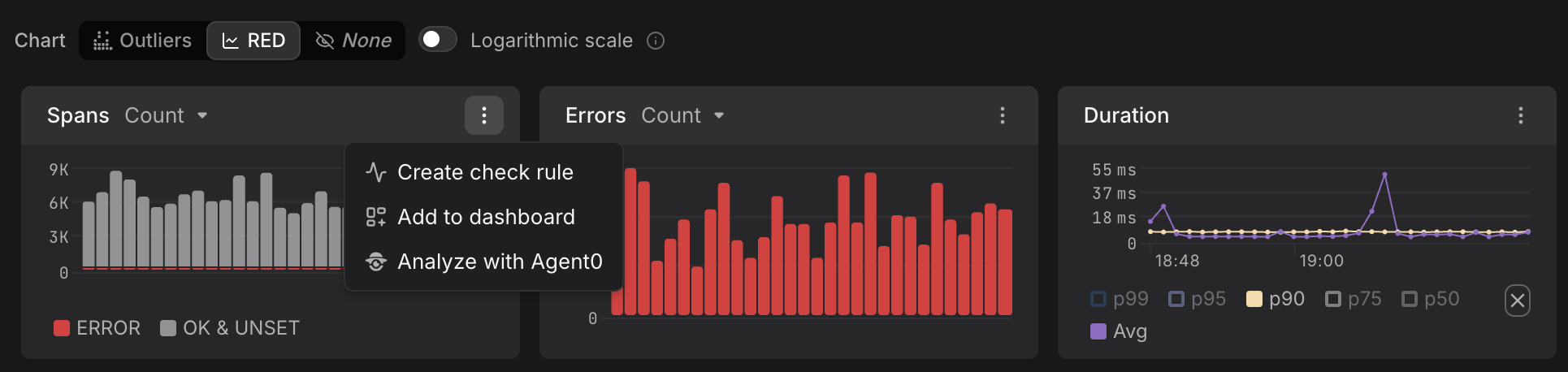
Built-in visualizations: The Service Catalog displays RED metrics for every service, and the Query Builder lets you analyze RED metrics across services, endpoints, and time ranges with automatic grouping by operation name, HTTP status code, and other dimensions.

-
Automatic metric calculation: Dash0 automatically calculates RED metrics from your OpenTelemetry traces without requiring manual instrumentation. Every service instrumented with OpenTelemetry spans automatically gets RED metrics computed at ingestion time, giving you immediate visibility into request rates, error rates, and latency distributions.
-
Unified resource views: Resource fragmentation can split your RED metrics across multiple resources when traces, logs, and metrics come from different sources with inconsistent attributes. Dash0's resource equality rules automatically merge these fragmented resources, ensuring your RED metrics reflect the complete picture of service health rather than partial views.
-
Alerting on RED signals: You can create alerts based on any RED metric—for example, trigger when error rate exceeds 5% or when p99 latency crosses 500ms. Dash0's alerting system supports threshold-based alerts on RED metrics with automatic anomaly detection.

Further Reading
- Operations: Standardized operation names for categorizing application behaviors
- Resource Equality: Automatic merging of fragmented observability data
- Resource Fragmentation: When observability data for a single system is split across multiple resources
- Synthetic Metrics: Query telemetry dynamically with on-the-fly calculated metrics