We all know Dynatrace is a powerhouse, especially with its AI-driven automation. But let's be real, that power often comes with a hefty price tag and a level of complexity that can make you question your life choices.
Hence, this article is meant to give you a straight-talk guide to Dynatrace alternatives that can give you the full-stack observability you need without the bill shock or the operational headaches. We're going to break down the real trade-offs, the hidden catches, and help you figure out if these tools truly fit your cloud-native stack and your budget.
1. Dash0

Dash0 is built for the modern cloud-native world, fundamentally designed around OpenTelemetry. It's not just "compatible"; it's OpenTelemetry-native, meaning it embraces the standard's data model and terminology from the ground up. This avoids the messy data mapping and context loss you often see with older, proprietary tools. Plus, Dash0 brings AI into observability in a way that actually helps, not just adds more noise. Dash0 is deeply focused on making telemetry more usable, more actionable, and frankly, more affordable.
What's good
Dash0's OpenTelemetry-native architecture is a game-changer. It means full support for all OpenTelemetry signals (logs, metrics, traces) and their relationships, like trace contexts in logs. This isn't just a marketing buzzword; it translates to better context and unified views without proprietary agents. The platform leverages OpenTelemetry's "resource" concept to tie all telemetry to a specific service or pod, giving you a single, unified view. Dash0 also uses PromQL for all signals, even logs and traces, so if you know PromQL, you're already ahead. This reduces the learning curve and leverages existing community knowledge.
Dash0’s SIFT framework is all about getting you to root cause faster. It starts with Spam removal, letting you drop noisy, irrelevant telemetry before it's stored and costs you money. This uses OpenTelemetry Transformation Language (OTTL) rules that can be exported for your own collector. Then, Dash0 improves telemetry with features like Log AI, which automatically detects and assigns severity to unstructured logs with high accuracy and no false positives. This means fewer "gray" logs and more actionable insights. Filtering and grouping are intuitive and interactive, letting you slice and dice data with a click, and Triage provides one-click automated root cause analysis, highlighting probable causes and correlations behind outliers. This is a huge time-saver when you're in the weeds.
Dash0 is a big believer in zero lock-in. Hence, its use of OTLP for data formats, PromQL for queries, and Perses for dashboards means your data, queries, and visualizations aren't trapped in its platform. You can manage dashboards as code and even migrate them to other platforms. Alerts also use the Prometheus standard, so they're portable.
Finally, Dash0’s transparent and user-centric pricing is a breath of fresh air. Dash0 charges by the number of logs, spans, and metric data points, not by data volume (GB) or user count. This means you can send rich metadata without worrying about exploding costs. Dash0 even provides real-time cost visibility dashboards. No per-user fees means everyone on your team can access observability data without extra charges.
The catch
Dash0 is a newer player, which means while their core OpenTelemetry-native features are cutting-edge, Dash0 might not have the sheer breadth of niche integrations or the decades of historical data that a giant like Dynatrace has accumulated. Dash0’s AI capabilities, while impactful (like Log AI), are focused on practical usability rather than abstract "chatbot" experiences. If you're looking for a vendor with hundreds of pre-built integrations for obscure, legacy systems, you might find us still building out that long tail. Also, while Dash0 offers powerful features like automated root cause analysis via Triage, their philosophy isn't about replacing human engineers with AI; it's about empowering them. If you're expecting a fully autonomous AIOps solution that makes all the decisions for you, that's not Dash0’s current focus.
The verdict
Dash0 is the clear choice for cloud-native startups and mid-sized companies already invested in OpenTelemetry and Prometheus, or those looking to move in that direction. If you're tired of opaque pricing, vendor lock-in, and proprietary tech that holds your data hostage, Dash0 offers a modern, affordable, and future-proof solution. Dash0 is for teams who want control over their observability stack, value open standards, and appreciate intelligent automation that genuinely simplifies complex tasks, rather than just adding features for features' sake.
Ready to see observability without boundaries?
Start your free Dash0 trial today!
2. Datadog
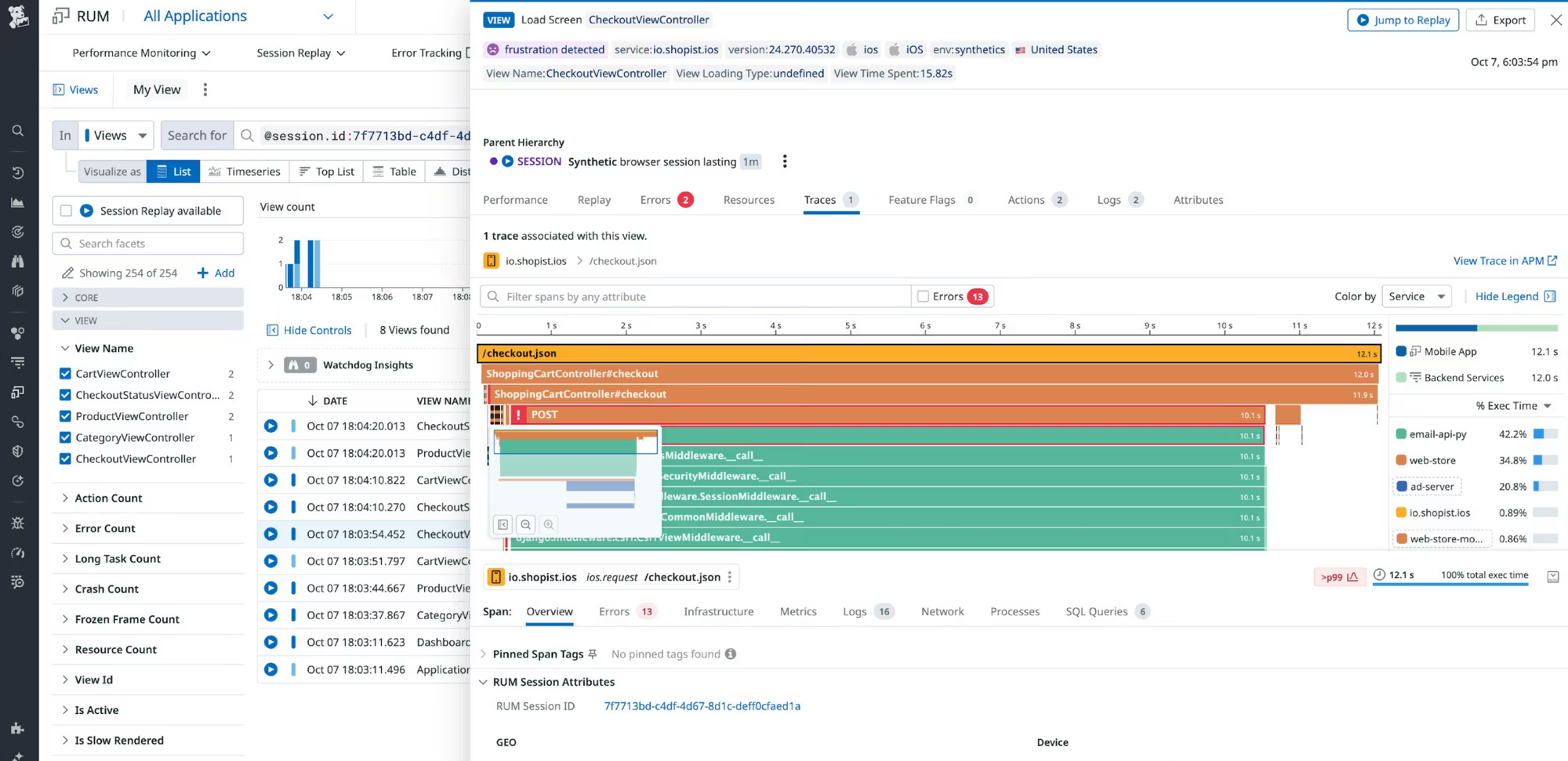
Datadog is a dominant force, an all-in-one SaaS platform that's aggressively expanded from infrastructure monitoring to APM, log management, RUM, synthetics, and a growing suite of security tools. It’s known for its extensive integrations—over 900 of them.
What's good
Datadog's primary strength is its unified platform and sheer breadth of features. It brings infrastructure monitoring, APM, logging, and more into a single, cohesive interface. For large enterprises, this consolidation can simplify operations by reducing tool sprawl. Its Watchdog AI engine automatically surfaces anomalies, cutting through noise, and its dashboarding experience is highly polished and powerful, with drag-and-drop widgets and collaborative notebooks. Instrumentation is also remarkably easy with its proprietary agent and "Single Step Instrumentation".
The catch
The most significant pain point with Datadog is its prohibitive and complex cost structure. Its multi-vector, usage-based pricing model is notoriously hard to predict, frequently leading to "bill shock". They charge for data ingest and indexing for logs, making you pay twice. What's worse, all OpenTelemetry metrics are treated as "custom metrics" and priced at a premium, creating a financial disincentive to use open standards. Their pricing often uses a high-water mark for hosts, meaning temporary scaling events can inflate your entire month's bill. Beyond cost, users report the UI can be overwhelming and complex for new users, with a steep learning curve. Their architectural core is proprietary, leading to vendor lock-in.
The verdict
Datadog is a fit for large enterprises with diverse, heterogeneous environments (mixing old and new tech) that prioritize a single, deeply integrated platform above all else, and have the budget—and tolerance for unpredictable costs—to match. If you're a cloud-native team aiming for OpenTelemetry adoption and cost predictability, Datadog's "OTel Tax" makes it a poor economic choice.
3. New Relic

New Relic, a pioneer in APM, has evolved into a comprehensive full-stack observability platform, unified into New Relic One. They've made a strategic effort to simplify pricing and offer a generous free tier.
What's good
New Relic's big play is its generous free tier (100 GB of data ingest and one full user per month). This makes it super accessible for developers and small teams to get started. They've consolidated pricing around two main vectors: data ingest and user seats, aiming for more transparency than some competitors. With its APM roots, New Relic still offers deep, code-level performance insights and a full-stack view. Their NRQL (New Relic Query Language) is powerful and flexible for custom queries and dashboards. They also support OpenTelemetry as a first-class citizen.
The catch
Despite efforts to simplify, cost at scale remains a major concern, especially for per-GB data ingest and expensive "Full Platform" user fees. There have been notable community concerns over "unethical billing," with reports of bills skyrocketing due to data generated by the New Relic agent itself. The platform still has a steep learning curve and UI complexity for some users. Free plan users have also reported aggressive sales tactics pushing for upgrades. While they support OpenTelemetry, their native agents are still a strong focus, creating a potential path to vendor lock-in if you lean too heavily on them.
The verdict
New Relic is a good option for development teams or mid-sized organizations needing deep APM and wanting to start with a robust free tier. If cost predictability at high scale is your absolute top priority and you're wary of hidden charges, be cautious and rigorously monitor your usage. Its simplified pricing concept is a step in the right direction, but the "unethical billing" incidents show that the devil is still in the details.
4. Splunk Observability Cloud

Splunk, a long-standing titan in log management and security, offers Splunk Observability Cloud as a comprehensive suite for APM, infrastructure monitoring, RUM, synthetic monitoring, and log investigation. It's built to be OpenTelemetry-native.
What's good
Splunk's definitive strength is its unmatched log search and analytics engine. Its proprietary Search Processing Language (SPL) is incredibly powerful for deep investigations across massive, unstructured datasets. Splunk Observability Cloud leverages this with its Log Observer Connect, providing a seamless link between metrics/traces and powerful log analytics without ingesting logs twice. It’s designed to be OpenTelemetry-native, using the Splunk Distribution of the OTel Collector for ingestion, and offers NoSample™ Full-Fidelity Tracing, capturing 100% of trace data. This is crucial for eliminating blind spots.
The catch
The most significant barrier to Splunk adoption is its extremely high cost. It’s notoriously expensive, and while Observability Cloud uses per-host pricing, the overall TCO still includes the cost of the separate Splunk Platform for full log storage and analysis. It also has a steep learning curve for SPL. While it's OpenTelemetry-native, the separation of the log data store from metrics and traces can introduce complexity compared to truly unified platforms.
The verdict
Splunk Observability Cloud is primarily for organizations already heavily invested in the broader Splunk ecosystem for log management and SIEM. If you're a long-time Splunk shop and need a modern, OTel-native APM solution that integrates with your existing setup, it makes sense. For greenfield projects or those without existing Splunk commitments, its high cost and fragmented log storage make it a less attractive option.
5. Honeycomb

Honeycomb is a SaaS-only platform built specifically for analyzing high-cardinality, high-dimensionality data in complex microservices. It's a strong advocate for OpenTelemetry.
What's good
Honeycomb's superpower is its fast analysis of high-cardinality data. It structures all data as "wide events," allowing engineers to slice and dice by any attribute (customer ID, feature flag, etc.) to debug "unknown unknown" problems. The BubbleUp feature is brilliant, automatically comparing outliers to baselines and highlighting the differentiating attributes, drastically speeding up root cause analysis. It's OpenTelemetry-native, meaning it's designed to ingest OTel data as a first-class citizen, and its pricing is simple and predictable, based solely on event volume, with no charges for users, cardinality, or custom metrics. This encourages deep instrumentation without fear of cost overruns.
The catch
Honeycomb is hyper-focused on event and trace-based debugging. It's not a full-stack observability platform in the traditional sense; it has less mature capabilities in classic infrastructure monitoring or unstructured log management. It also lacks features like synthetic monitoring. There's a learning curve for teams accustomed to metric-centric monitoring, as it requires a shift in mindset to event-based investigation.
The verdict
Honeycomb is ideal for developer-centric teams running complex, distributed microservices that need to debug novel production issues quickly. If your primary pain is sifting through massive amounts of high-cardinality data to find the needle in the haystack, and you're bought into an observability-driven development culture, Honeycomb is a top contender. Just know you'll likely need other tools for traditional infrastructure monitoring or synthetic checks.
6. IBM Instana

IBM Instana is an automated APM solution that focuses on providing real-time visibility into dynamic, complex application environments, particularly for microservices and cloud-native architectures.
What's good
Instana's key differentiator is its fully automated discovery, mapping, and tracing. Its "OneAgent" automatically detects and maps all components in dynamic environments, providing a real-time dependency graph. It offers 1-second metric granularity and captures 100% of traces, aiming for zero-configuration observability. This automation significantly reduces manual setup and maintenance overhead, making it appealing for large enterprises with rapidly changing environments. It also provides strong AI-powered anomaly detection and root cause analysis.
The catch
Like other enterprise-grade solutions, Instana comes with a premium price tag, which isn't always transparently available and can be based on a per-host model. While it's strong on APM and infrastructure, its broader observability features (like log management beyond trace correlation) might not be as comprehensive or flexible as dedicated log platforms. The user interface, while powerful, can be complex for new users due to the sheer amount of automatically collected data. For teams deeply invested in OpenTelemetry, Instana integrates but isn't OpenTelemetry-native in the sense that it relies heavily on its proprietary agent for its core automation.
The verdict
IBM Instana is a strong candidate for large enterprises with complex, dynamic microservices architectures that prioritize highly automated, zero-config APM and root cause analysis, and are willing to pay for that convenience. If you need deep, instant visibility into your application stack without manual setup, and you're managing highly distributed systems, Instana can deliver. However, budget-constrained teams or those prioritizing a pure OpenTelemetry-native approach might find its proprietary nature and cost less appealing.
7. Elastic Observability (Kibana + Elastic APM, Logs, Metrics)

Elastic Observability is built on the ubiquitous open-source ELK Stack (Elasticsearch, Logstash, Kibana). It provides a unified platform for logs, metrics, traces, RUM, and synthetic monitoring, leveraging Elasticsearch's powerful search capabilities.
What's good
Elastic's greatest strength is its powerful search and analytics engine, Elasticsearch. It delivers exceptionally fast search and indexing for massive log data volumes. Its open-source foundation (ELK Stack) provides a low-friction entry point and allows for self-hosting and maximum control, avoiding vendor lock-in. It offers a unified experience for logs, metrics, and traces within Kibana, and is fully OpenTelemetry-native with its Elastic Distributions of OpenTelemetry (EDOT). Compared to Splunk, it's often seen as a more cost-effective solution, especially for self-managed deployments.
The catch
The primary limitation of Elastic is the complexity of setup and management, especially for self-hosted deployments. Optimizing a large-scale Elasticsearch cluster requires significant expertise. While the managed Elastic Cloud service removes this burden, it introduces its own challenge: confusing and potentially high cloud costs, with users reporting unexpected bills. The Kibana Query Language (KQL) also has a learning curve for advanced queries. Its APM solution, while improving, is generally considered less mature and automated than APM-native competitors.
The verdict
Elastic Observability is an excellent choice for engineering teams with a strong need for powerful log search and analytics, and a preference for an open, flexible platform. If you have in-house expertise in managing distributed systems or are willing to pay for the managed cloud service, and you value control over your data, Elastic is a solid alternative. However, if you're looking for a "zero-config" solution with minimal operational overhead, you might find it too complex.
8. SigNoz

SigNoz positions itself as a direct, open-source alternative to all-in-one observability platforms like Datadog and New Relic. It offers logs, metrics, and traces in a single, unified tool, built fundamentally as OpenTelemetry-native.
What's good
SigNoz's primary strength is its cost-effective, open-source alternative to expensive incumbents. It delivers an all-in-one experience (logs, metrics, traces in one UI) on an OpenTelemetry-native foundation, which means no vendor lock-in and best-in-class support for OTel semantic conventions. The use of ClickHouse as its storage backend provides significant performance advantages for high-speed query performance on large datasets, potentially leading to lower infrastructure costs. Its pricing model is simple and transparent, based purely on usage (GB ingested, million samples), with no per-user or per-host fees. This directly addresses a major pain point of other platforms.
The catch
As a relatively newer player, SigNoz has a less mature feature set and fewer pre-built integrations compared to established giants. While it covers core observability pillars, it might lack some of the more advanced or niche features found in larger commercial tools. For the self-hosted version, there's still an operational effort to deploy, manage, and scale the ClickHouse database. Its market presence and public user review history are still growing.
The verdict
SigNoz is an excellent choice for startups and cost-conscious engineering teams building on modern, cloud-native stacks. If you're committed to OpenTelemetry and want a unified, all-in-one observability solution without the prohibitive costs and vendor lock-in of the "Big Three," SigNoz offers a compelling open-source alternative that you can self-host or use as a managed cloud service.
9. Grafana Labs (Grafana, Loki, Tempo, Mimir)

Grafana isn't just a visualization tool anymore; it's a composable stack of open-source projects—Loki (logs), Grafana (visualization), Tempo (traces), and Mimir (metrics)—offering a complete observability platform. It’s available both as open-source (OSS) for self-hosting and as a fully managed SaaS (Grafana Cloud).
What's good
Grafana's core strength is its unmatched dashboarding and visualization engine. It's universally acclaimed for its beautiful, powerful, and highly customizable dashboards that can pull data from hundreds of sources simultaneously. Its open and composable nature means no vendor lock-in, and its extensive plugin ecosystem allows flexibility in choosing data backends. It's natively designed for OpenTelemetry and Prometheus. For those seeking a managed solution, Grafana Cloud bundles the full power of the stack with a generous free tier. It also has a massive and active open-source community.
The catch
While powerful, Grafana's flexibility can lead to complexity and a steep learning curve for beginners. The alerting system is widely criticized as overly complex and unintuitive since its overhaul, often requiring knowledge of Go templating for custom notifications. For self-hosters, the operational overhead of managing the backend components (Loki, Mimir, Tempo) is substantial, requiring significant in-house expertise. Grafana Cloud's pricing, while often cheaper than Datadog, can still be unpredictable and lead to "bill shock", with reports of unexpected charges after brief tests.
The verdict
Grafana (and its Cloud offering) is ideal for engineering teams that have embraced a Prometheus-based, open-source monitoring philosophy and prioritize flexibility, control, and best-in-class visualization. If you have the in-house expertise to manage a distributed stack or are willing to accept potential cost surprises on the managed service, it's a viable alternative. However, if you need a simple, "it just works" all-in-one platform with easy-to-configure alerting, you might find it challenging.
10. LogicMonitor

LogicMonitor is a SaaS-based infrastructure and application monitoring platform that provides unified observability across on-premises, hybrid, and multi-cloud environments. It focuses on automated discovery and pre-built dashboards.
What's good
LogicMonitor offers a comprehensive approach to infrastructure monitoring with automated discovery of devices, applications, and services across diverse environments (on-prem, cloud, hybrid). It comes with a vast library of pre-built dashboards, alerts, and integrations (called "LogicModules"), significantly reducing setup time for common technologies. Its focus on out-of-the-box monitoring can be a major time-saver for IT operations teams. It provides a unified view of metrics, logs, and some tracing capabilities, aiming for a single pane of glass for operational insights.
The catch
While comprehensive for infrastructure, LogicMonitor's APM and tracing capabilities are generally considered less mature or deep than dedicated APM tools like AppDynamics or OpenTelemetry-native solutions. Its pricing model can be complex and tied to device count, potentially becoming expensive for highly dynamic, containerized environments. Users sometimes report that customizing beyond the pre-built modules can be challenging or require significant effort. Its proprietary agent and data model mean it's not OpenTelemetry-native, which can lead to vendor lock-in.
The verdict
LogicMonitor is best suited for IT Operations teams in mid-to-large enterprises with diverse infrastructure (especially hybrid or on-premises) who prioritize out-of-the-box monitoring, automated discovery, and pre-configured alerts. If you're looking to monitor traditional infrastructure alongside some modern workloads, and value reducing initial configuration time, it's a solid choice. However, if your primary need is deep, OpenTelemetry-native application tracing, flexible data ingestion, or highly predictable cloud-native pricing, you might find it lacking compared to other alternatives.
11. Sematext

Sematext offers a full-stack monitoring solution that bundles logs, metrics, RUM, synthetics, and tracing into a single platform. It aims for transparency and predictability in its pricing, offering a modular approach.
What's good
Sematext provides a comprehensive suite of monitoring tools (logs, metrics, RUM, synthetics, APM/tracing) in one platform, aiming to simplify the observability stack for users. It emphasizes transparent, per-app pricing, which can offer more predictability than complex multi-vector models. The platform offers a good balance between features and ease of use, making it accessible for SMBs and DevOps teams. It also provides a free trial and a free tier for some services.
The catch
While it offers a wide range of features, Sematext might not have the same depth or advanced capabilities in every single area (e.g., highly specialized APM or AI-driven root cause analysis) as a dedicated, best-of-breed solution or a more mature enterprise platform. Its pricing model, while transparent, can still be complex if you combine many different services and scale up. Some users might find the UI less polished than some of the market leaders. As a smaller player, its community and third-party integrations might not be as extensive.
The verdict
Sematext is a strong contender for SMBs and mid-market companies that need a comprehensive, yet cost-effective and relatively simple full-stack observability solution. If you're looking for an all-in-one platform without the pricing complexity or operational burden of the "Big Three," and you value transparent, modular pricing, Sematext offers a compelling package. It's a good choice if you want to avoid tool sprawl without sacrificing key observability pillars.
12. Better Stack

Better Stack is a comprehensive infrastructure monitoring platform that unifies log management (Logtail), uptime monitoring, and incident management (Better Uptime) into a single, user-friendly platform.
What's good
Better Stack's primary strength is its integrated and user-friendly platform that combines logging, uptime monitoring, and incident management. It simplifies the observability stack for teams who don't need enterprise-grade complexity. It excels in real-time monitoring and visualization, with high ratings for its immediate insights and user-friendly dashboards. The platform offers robust incident management and alerting, including on-call scheduling, flexible escalations, and unlimited voice/SMS alerts, features often found in more expensive, dedicated tools. It's also praised for its value, even in its free tier.
The catch
A commonly reported issue is the initial setup process, which can be complex despite the platform being easy to use once configured. While it covers core logging and uptime, it's not as deep in advanced observability features like sophisticated APM or distributed tracing as some competitors. Some users have reported occasional performance issues with the UI and bugs with Slack alerts. It's also a newer company, so its ecosystem and long-term track record are still building.
The verdict
Better Stack is a great fit for small to mid-sized engineering or DevOps teams looking for a simple, unified solution for logging, uptime monitoring, and on-call management. If you prioritize a clean UI, straightforward pricing, and don't need the deep, enterprise-grade features of a Dynatrace, Better Stack offers a compelling, integrated experience that reduces tool sprawl.
13. ManageEngine Application Monitor

ManageEngine Applications Manager is an enterprise-grade APM tool that offers comprehensive performance monitoring for business-critical applications, servers, databases, and custom applications across physical, virtual, and cloud environments.
What's good
ManageEngine Applications Manager offers broad application coverage, supporting a wide array of application servers, databases, web servers, and custom applications, making it suitable for diverse enterprise environments. It provides deep-dive transaction tracing, code-level diagnostics, and root cause analysis capabilities. Its strength lies in its on-premises deployment options alongside cloud, which appeals to organizations with strict data residency or hybrid infrastructure requirements. It’s often considered a more cost-effective option for comprehensive APM compared to some of the higher-priced market leaders.
The catch
While comprehensive, its UI/UX can feel less modern or intuitive compared to newer, cloud-native focused observability platforms. The learning curve can be steep due to the breadth of features and configuration options. Its data model and agent architecture are typically proprietary, meaning it's generally not OpenTelemetry-native, which can lead to vendor lock-in and a less open ecosystem for data ingestion. Its AI capabilities for AIOps are often less sophisticated or automated than a specialized AI-first platform like Dynatrace.
The verdict
ManageEngine Applications Manager is a solid choice for traditional enterprises or those with significant on-premises and hybrid infrastructure who need a comprehensive, agent-based APM solution. If you prioritize broad application coverage, robust monitoring for a variety of traditional IT components, and a potentially lower price point than top-tier APM vendors, it's worth considering. However, if your focus is exclusively cloud-native, OpenTelemetry adoption, or cutting-edge AI-driven automation, you might find more modern alternatives better suited to your needs.
Final thoughts
The observability landscape is a wild west, but one thing's clear: vendor lock-in and opaque pricing are the real enemies. Dynatrace is a beast, no doubt, but that raw power often means you're signing away control and predictable costs. The alternatives we've broken down offer different paths, whether it's embracing open standards, focusing on developer-centric debugging, or providing transparent pricing.
For the cloud-native team of today and tomorrow, the answer isn't just about collecting more data; it's about collecting the right data, making it actionable, and doing it without bleeding your budget dry. That's why OpenTelemetry-native solutions that prioritize transparent pricing and genuine usability are winning.
Ready to get real observability without the hassle?

