


This blog explores the groundbreaking advancements in monitoring and observability provided by OpenTelemetry, enabling developers to gain deeper insights and improve system performance.
Readers will gain a solid understanding of how OpenTelemetry's native observability tools empower developers and organizations to achieve greater visibility into their systems, leading to improved performance, reliability, and user experiences.
OpenTelemetry is the second largest CNCF project by number of contributors. Founded in 2019, OpenTelemetry has been steadily gaining traction and mindshare in the community for half a decade. However, the observability industry has yet to fully embrace OpenTelemetry, often using it as a secondary, largely untapped alternative to their proprietary means of collecting and utilizing telemetry.
In this light, it is unsurprising that the term “OpenTelemetry-native” has come up recently. In Selling the Vision, Austin Parker states that there is a need for truly OpenTelemetry-native tools. In Observability n.0, Sahil Patwa predicts that the next breakout observability company will be OpenTelemetry-native.
Neither post provides a detailed description of what an OpenTelemetry-native observability tool would look like. However, Austin envisions a tool that "[...] actually leverages our context layer and uses it well. Sampling as a first-class, seamless part of your observability stack. Automatic routing of telemetry based on class and type, and query interfaces that work across disparate data stores. New types of visualizations, and timelines as a primary visualization for user journeys."
At Dash0, we agree! We firmly believe OpenTelemetry is the emerging and future de-facto standard for collecting, transmitting, and sharing observability data. The OpenTelemetry Protocol (OTLP) is the wire-format for sharing telemetry data that, as an industry, we have been needing for decades. And OpenTelemetry’s semantic conventions are key to machine-processable and contextualized telemetry that can be queried across teams and organizations. Furthermore, it will become the foundation for training open and standardized AI models.
Dash0 is committed to building a modern, excellent OpenTelemetry-native observability tool and providing free tools, such as OTelBin.io, to assist users in successfully adopting OpenTelemetry.
What does an Open-Telemetry-native observability tool look like?
There are many requirements that go into defining what is an OpenTelemetry-native observability tool. This is our list, roughly sorted from most to least important. (Although, the nature of your systems and previous experience with observability tools may lead you to a somewhat different sorting.)
1. All OpenTelemetry signals, fully integrated
As of early 2024, OpenTelemetry supports spans (tracing), logs and metrics; profiling is in the works.

These types of telemetry, a.k.a. signals in the OpenTelemetry lingo, are related with one another through the common concept of resource (see 4. Resource centricity), but also through signal-specific relations. For example: logs can specify the trace context (trace and span identifiers) that was active when the log was created, allowing you to “link back” from logs to spans. Metrics can be annotated with exemplars, namely trace contexts of “example” spans that were active as the metric was modified (e.g., the counter was incremented). Profiling data will also be related to tracing via the trace context.
If supported well by the observability tool, these correlations among signals enable the users to visualize, navigate, and query in their triaging and troubleshooting telemetry that describes different aspects of how a system is performing. In most solutions today, no natural (data layer) connection exists between data types, making troubleshooting laborious and slow.
2. Contextualized telemetry with semantic conventions
Telemetry without context is just data. Is 500 ms response time good or bad? Well, that depends very much on which system has that response time, whether it is in production (and where) or not and, more generally, what are the Quality of Service expectations on its behavior.
However, consistently describing which system is emitting telemetry is a challenge that grows more difficult as organizations grow. To this end, OpenTelemetry has semantic conventions: a shared, growing vocabulary of names and concepts used to describe telemetry and the systems it documents while minimizing metadata fragmentation.
Consistent metadata through semantic conventions facilitates the efficient searching and filtering of all telemetry data by the users to aid in analysis, especially troubleshooting.
Native OpenTelemetry tools can leverage tags defined by the semantic convention. This enables them to harness semantics to aid users in their tasks. For troubleshooting purposes, tools can illustrate telemetry data in the context of the cloud or orchestration platform, guiding users to the correct resources (see 4. Resource centricity). Additionally, the conventions facilitate the integration of logs, traces, and metrics, aiding in troubleshooting efforts.
Furthermore, semantics assist in pinpointing and resolving issues on an attribute level. For instance, they can illustrate how a request's performance was adversely affected for a specific user, users in a certain region, or users employing a particular device. (see 9. One-click comparison of telemetry across resources and timeframes)
3. Automated quality control for telemetry metadata
Some semantic conventions are implemented in OpenTelemetry SDKs, e.g., through resource detectors and automated instrumentations. Others require configuration by the user, or adherence when implementing custom instrumentations and telemetry processing.
Virtually all organizations larger than a pizza team have had issues with metadata consistency, using different names for the same concept. In our experience, it’s not uncommon to find observability datasets where the keys aws.bucket.name, aws.s3.bucket, aws.s3.bucket.name, aws.s3.bucket_name are all in use at the same time by multiple teams, or even across multiple components run by the same team. Another classic inconsistency is annotating different subsets of metadata, so that, for example, the on-call teams are not consistently or accurately tagged for all components. These inconsistencies degrade searching, dashboarding, alerting, and almost all other types of manual or automated analysis and the organizational processes that rely on it.
An OpenTelemetry-native tool should detect misuse of namespaces through keys that are not mandated in specifications, or that “look too similar” with one another (e.g., short edit distance and similar values). Sometimes the mistake is by omission, where entire categories of metadata are missing altogether (“these spans have no resource attribute about what infrastructure emits them”).
An OpenTelemetry-native tool would intrinsically extract insights by standardizing and ensuring formatting compliance.
4. Resource centricity
The concept of resource is one of OpenTelemetry's most important innovations. Resources are common across all signals to specify which system the telemetry describes (“it is the Kubernetes pod with UID 12345678 running on a cluster in the us-east-1 AWS region”). Resources can be anything: a container, a Kubernetes pod, a host, a service managed by your Cloud provider, or another 3rd party. Resources can also include metadata not standardized in semantic conventions, like an organization's preferred way of tagging which team owns or operates a specific component, or which cost center it counts against.
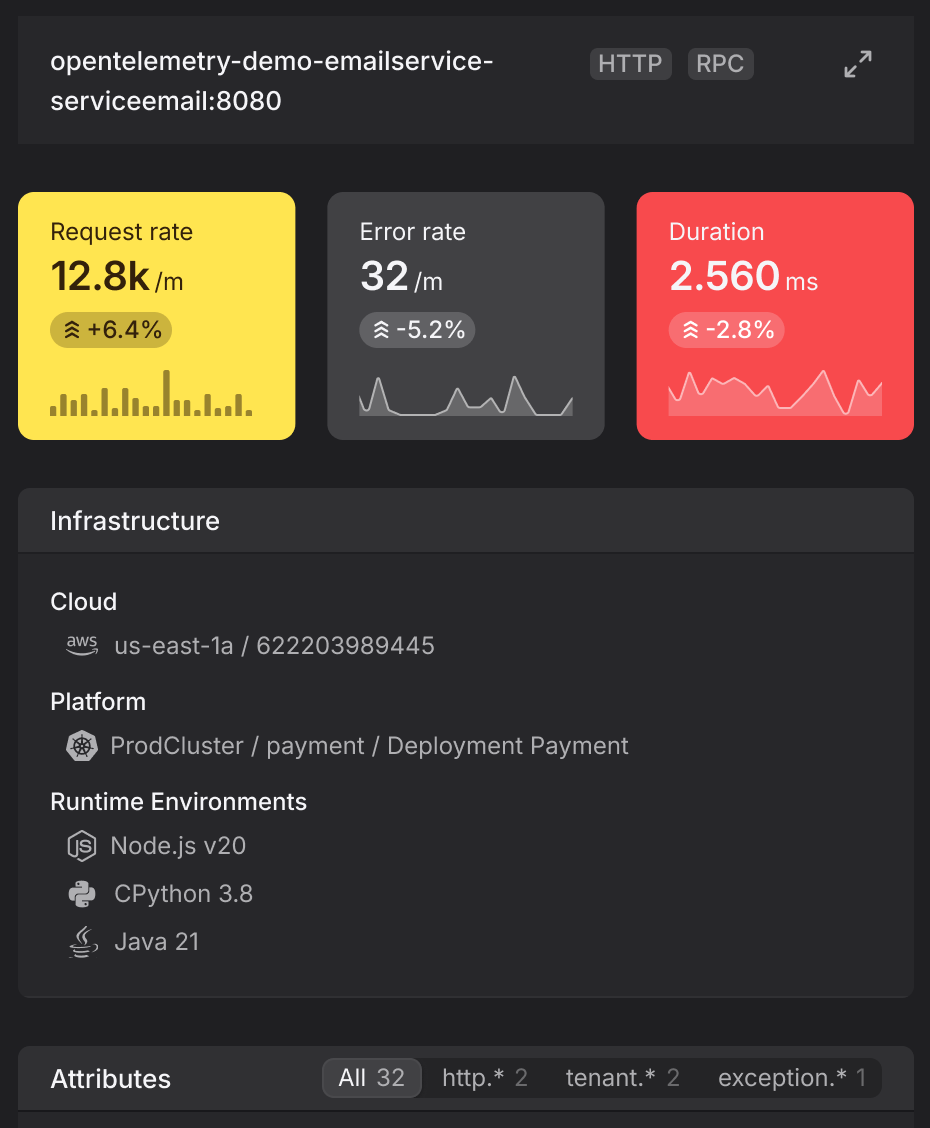
Resources tie related telemetry together. The resource-centric approach offers more context for users to understand relationships between resources and linked telemetry, especially because cloud-native applications are composed of multiple levels of abstraction, and issues can span several logical levels, encompassing infrastructure, orchestration, components, and their interactions. Hence, resources provide means of structuring telemetry data sets to align them with users' mental models of their systems and architectures.
An OpenTelemetry-native tool should provide resource-centric visualizations and offer various perspectives for viewing their dependencies and groupings. For example, you could map service dependencies grouped by AWS zones or Kubernetes pod dependencies grouped by Kubernetes cluster. Additionally, the tool should display relevant information about these resources and groups derived from the underlying telemetry data, irrespective of how the data is collected, using the metadata inside the resources to bring together telemetry from various sources.
5. Seamless integration with the cloud-native open-source ecosystem
Albeit being the second largest CNCF project by number of contributors, OpenTelemetry is but one part of the growing cloud-native ecosystem. An OpenTelemetry-native system must integrate seamlessly with other cloud-native platforms and standards. For example, an OpenTelemetry-native tool should be easily integrated into the operations of workload orchestration tools, like the standard Kubernetes autoscaling mechanisms.
Also, “OpenTelemetry-native” does not mean “OpenTelemetry only”! An OpenTelemetry-native tool must be able to ingest and process telemetry not conveyed over OTLP. For example: Prometheus is the de-facto standard of time series collection and processing in the cloud-native ecosystem, which is unlikely to change in the foreseeable future. An OpenTelemetry-native tool should interoperate with Prometheus via 100% compatible PromQL and Prometheus remote-write support, and be able to reuse Prometheus alert rules and forward alerts to existing Alertmanager setups.
Similarly, there are many agents that collect and emit logs in a variety of protocols other than OTLP. It should be straightforward to integrate an OpenTelemetry-native observability tool with the likes of fluentd, Beats, Syslog, and the like.
The value of aligning to the cloud-native ecosystem has an important human aspect that goes well beyond the technical capabilities: it enables its users to reuse their knowledge and the work of various communities, like public documentation, training, dashboards, alert rules, and, generally, established and emerging best practices.
6. One query language to rule them all (signals)
OpenTelemetry signals are correlated (see 1. All OpenTelemetry signals, fully integrated), and these correlations must be integrated with how the data is queried. Offering different query languages for different signals, and treating signal types as data silos, undermines the value of OpenTelemetry as a whole.
And while OpenTelemetry does not provide a query language (yet?), the cloud-native observability world has, by and large, one “lingua franca” of sorts: PromQL. Granted, PromQL does not solve all use cases: for example, it does not lend itself to returning lists of logs or spans. But most of querying use cases in observability, like alerts and custom dashboards, are overwhelmingly about querying time series, even if processing and aggregating spans or logs calculate those.
Moreover, query languages need support that goes beyond their syntax. Users need and deserve excellent support in composing valid queries that answer their questions. As an industry, we should hold ourselves to the same standards of tooling quality for query languages, as we do for programming languages. After all, both are ways of encoding logic to manipulate data, often in complex ways and at scale.
Adopting a standardized language offers numerous advantages in fostering effective communication and seamless collaboration within teams that utilize diverse tools. Firstly, it establishes a common language, enabling team members to communicate clearly and concisely, regardless of their preferred tools or technologies.
Additionally, a standardized language facilitates sharing queries beyond personal and team boundaries.
Furthermore, a standardized language supports the creation of a centralized knowledge base or repository. When queries and information are expressed consistently and structured, they become easily searchable and accessible to all team members.
A good example of sharing alerts based on PromQL queries is the Awesome Prometheus Alerts project which defines and shares a set of best practices for different technologies.
7. Health and alerting system
The best observability tool is the one that tells you when there is something important to look at. Proactive health monitoring and alerting capabilities ensure that users are promptly notified of potential issues to take timely corrective actions, minimize downtime and maintain optimal system performance.
The alerting system should be based on the telemetry, resource, and query concepts described above and seamlessly integrated into the UI, APIs and Infrastructure as Code (IaC) tooling.
The ways alerts are specified should leverage OpenTelemetry signals and resources. Two primary approaches are required to specify what constitutes something to alert about:
1. Threshold-based alerts: Define thresholds for the signal, like the maximum error rate acceptable over a certain timeframe (“max 5% errors over 1 hour”) and telemetry crossing these thresholds triggers an alert.
2. Anomaly detection: The tool should also offer optional anomaly detection capabilities that combine baselining and forecasting, and are tailored to the nature of the telemetry processes. For example, seasonality may work differently for HTTP requests for some systems than CPU consumption.
The checks and resulting health statuses should be prominently and consistently displayed in the UI. Configuring new alerts and modifying existing ones should be straightforward and accessible from the same interface where the signals and resources are displayed. And most importantly, it must provide immediate feedback and guidance on how the modifications would have changed which alerts were triggered and when.
Special care should be applied to default alert rules. As new users onboard to the tool, or onboard new systems to be monitored by the tool, they should get value out of it as early and with as little effort as possible. Early gratification (the “wow” moments) are an important step towards creating positive loops where the tool is used at the best of its capabilities to provide the most possible value.
8. Sampling, data control, and scale
For users transitioning from proprietary tools to OpenTelemetry, they gain unprecedented control over their telemetry data. A common complaint about current tooling is that they often collect and store excessive telemetry by default, resulting in disproportionately high storage and processing costs relative to the value they provide.
The fine-grained control in OpenTelemetry of what telemetry to collect, how to sample and aggregate it, and the correlations between signals, is the foundation to re-imagine the economics of observability.
OpenTelemetry-native tools should provide easy-to-use facilities for users to balance their needs with the costs of processing and storing the telemetry. For example, the tool should provide an easy way to configure telemetry sampling to control costs. This goes beyond the common head/tail sampling by leveraging correlations between signals (e.g., exemplars) to retain as much meaning as possible while reducing the volume of stored telemetry. Moreover, AI technology can help aggregate and condense log and trace data to simplify and reduce the cost of storage and searching.
It’s important to note that users already have some of this control. The flexible and extensible OpenTelemetry collector architecture enables scalable collection, processing, and forwarding of telemetry data. It can act as an adapter, receiving telemetry in one format and transforming it into others. It offers means of sampling telemetry, albeit requiring manual fine-tuning. It also enables the filtering and masking of telemetry for security and governance reasons, transforming and enriching the data to provide more context, and dispatching data to different backends. Our free and open-source OTelBin.io lets users configure OpenTelemetry Collector in an easy and graphical way.

OpAMP adds real-time (re)configuration for deployed OpenTelemetry collectors, reducing the time and effort needed to roll out configuration changes across large fleets.
9. One-click comparison of telemetry across resources and timeframes
OpenTelemetry signals are often referred to as “having high-cardinality”. High cardinality, in the context of observability, refers to the fact that metrics, logs or traces may have many pieces of metadata (dimensions) and many unique values for them, like annotating account ids and similar attributes on every log or span.
Telemetry’s cardinality is a powerful tool in diagnosing and analyzing the underlying causes of an issue. Similarities and differences across specific metadata steer the troubleshooting and allow to formulate and validate hypotheses quickly. Humans, on their own, are not well-suited for this type of analysis, as it consists of comparing numerous signals with hundreds or thousands of attributes; machines, on the other hand, excel at it, iteratively detecting patterns in large volumes of data and dimensions, and offering them up for humans to evaluate.
An OpenTelemetry-native tool should provide easy mechanisms to compare large-cardinality datasets across:
- Time: What changed regarding metadata in these time series between now, with the problem occurring, and before it? Is it only the values spiking, or are there patterns in the metadata of the data points that can shed a light? For example, there is a much stronger activity clustering for specific tenants than before.
- Resource clusters: What are the differences between this set of resources, which is experiencing issues, and that other set, which seems to operate just fine. For example, what are the differences between my deployment on the EMEA cluster, which is currently on fire, and the one in APAC, which seems to be doing just fine?
- Metadata clusters: Of all the issues that are occurring, are there sets of metadata that are more prevalent than others? For example, if AWS
us-east-1is down, chances are that the first affected components were those deployed in it, and annotated withcloud.region_id = us-east-1. As more systems get under stress other regions may be affected too. But comparing between clusters of metadata can also help: for example, the tool should be able to compare all the erroneous spans in a timeframe with the spans without errors to identify patterns that might indicate the cause of the errors.
Comparing the relevant data should be intuitive, easy to comprehend and to iterate upon. The user experience will make or break its usefulness to non-expert end users. Moreover, the comparison feature should be contextually available, easier to reach for the users, and more relevant to the data being seen.
10. Fully-integrated Real User Monitoring
Real User Monitoring (RUM) is the monitoring capability that tracks what a user does on client devices, like browsers, mobile applications or Internet of Things (IoT) devices, and relates it with what happens server-side to service the page loads, API requests and so on. RUM is critical to understanding and optimizing the user experience, ensuring high satisfaction and engagement of end users with the services they consume.
While OpenTelemetry does have, in its JavaScript SDK, facilities to trace the JavaScript code of a website running in the users’ browsers, it treats RUM by and large as tracing data. We are not quite sure that that is the right approach for several technical reasons related to the conceptual differences between spans and application sessions and implementation details like performance overhead and transmission mechanisms.
Irrespective of what turns out to be the best way to do RUM with OpenTelemetry, it must fit seamlessly with the other signals, with resources, and with the rest of OpenTelemetry.
11. Export telemetry with OTLP and other open-source protocols
OpenTelemetry data has uses beyond observability, like testing or security. An OpenTelemetry-native observability tool should be able to forward the telemetry it receives via OTLP and other formats to other tools, optionally including enrichments, sampling, aggregations, and other processing artifacts. After all, telemetry wants to be free.
Moreover, having your observability tool exporting data to another is an important and often missing ingredient in avoiding lock-in, enabling users to evaluate or perform migrations between tools to compare “apples to apples.”
Onwards to the future of observability
At Dash0, we are committed to building an OpenTelemetry-native observability tool that meets the requirements listed above, contributing to the OpenTelemetry project, and providing free tools to assist users in successfully adopting OpenTelemetry.
